2022년 시스템 구조 기출문제 정리 입니다.
Agenda
1.2의 보수 계산 - 10진수 -5의 2의 보수 (79번 문제)
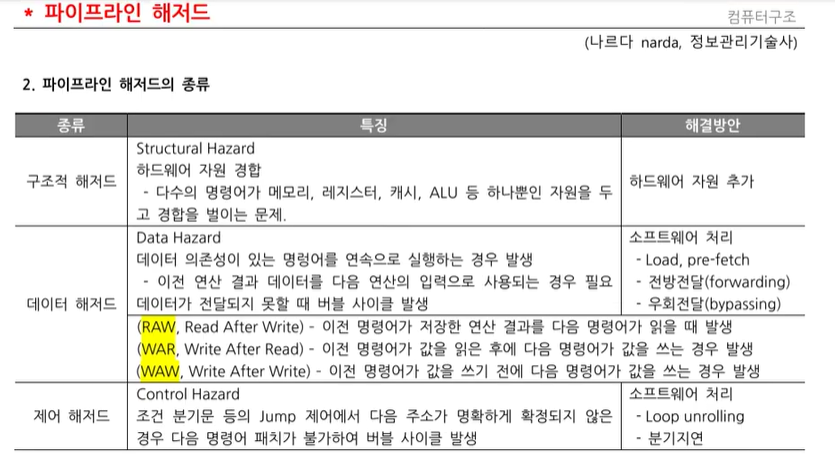
2. 파이프라인 - Hazard 종류 (84번 문제)
3.ipv4. Ipv6. 헤더정보 단편화 발생시 변경되지않는정보 (90번문제)
4. NAT 유형 (93번 문제)
5. 활성화 함수 - 시그모이드, ReLu (94번 문제)
6. Spark 설명 (98번 문제)
1.2의 보수 계산 - 10진수 -5의 2의 보수 (79번 문제)
=> 풀이) 5의 2진수 = 0101 -> 1의 보수 : 1010 -> 2의 보수: +1 : 1011 이 답임
- 보수 : 반전의 의미, ( 1-> 0, 0->1로 전환하는 것임)
1의 보수
0 -> 1
1 -> 0
1의 보수에서 +1을 하는 것이 2의 보수 - 아래 설명 참조
즉 숫자를 반대로 하고, 부호도 반대로 한다.

(주의) 음수일때.

1) 1차에서 13의 2의 보수를 취한 결과가 "0011", -> 1010 + 0011 (1차 2의 보수를 취했음으로 "-"에서 "+"로 계산해 주면 " 1101" 이 되며, 이는 그 앞단에 숫자가 없음(캐리가 없음) => 그럴 경우는 연산 결과에 다시 2의 보수를 취해 주면, 정답임
2. 파이프라인 - Hazard 종류 (84번 문제)
- 파이프라인은 순차구조임, 그래서, 파이프라인 중 한곳이 비어있으면, 명령어처리가 안되는 문제점이 있다.
https://www.youtube.com/watch?v=L4uBy9_g1PM

3.ipv4. Ipv6. 헤더정보 단편화 발생시 변경되지않는정보 (90번문제)
https://www.youtube.com/watch?v=jWEd0ttd8as
- IP : Newwork layer (3계층)

- 검사합 = Parity check = checksum
https://www.youtube.com/watch?v=TpanXjz5Dgo
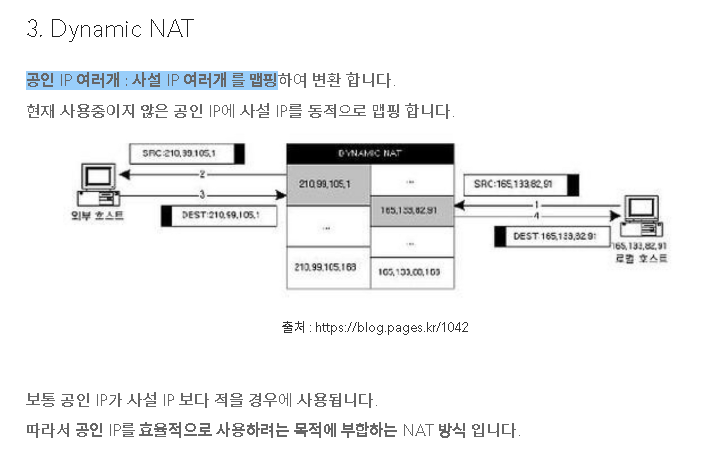
4. NAT 유형 (93번 문제) - 정답 -3
93. NAT(network address translation)에 대해 올바 르게 설명한 것을 모두 고른 것은?
가. DNAT(Dynamic NAT) 방식에서는 내부(사설) 네트 워크의 사설 IP주소가 외부에 공개되므로, 외부 컴퓨터는 사설 IP로 내부 컴퓨터에 접속한다.
나. SNAT(Static NAT) 방식에서는 사설 IP와 공인 IP가 일대일로 매핑된다.
다. PAT(Port Address Translation) 방식에서는 소수의 공인 IP를 내부 네트워크의 다수의 컴 퓨터가 공유해서 사용할 수 있다.
① 가, 나
② 가, 다
③ 나, 다
④ 다
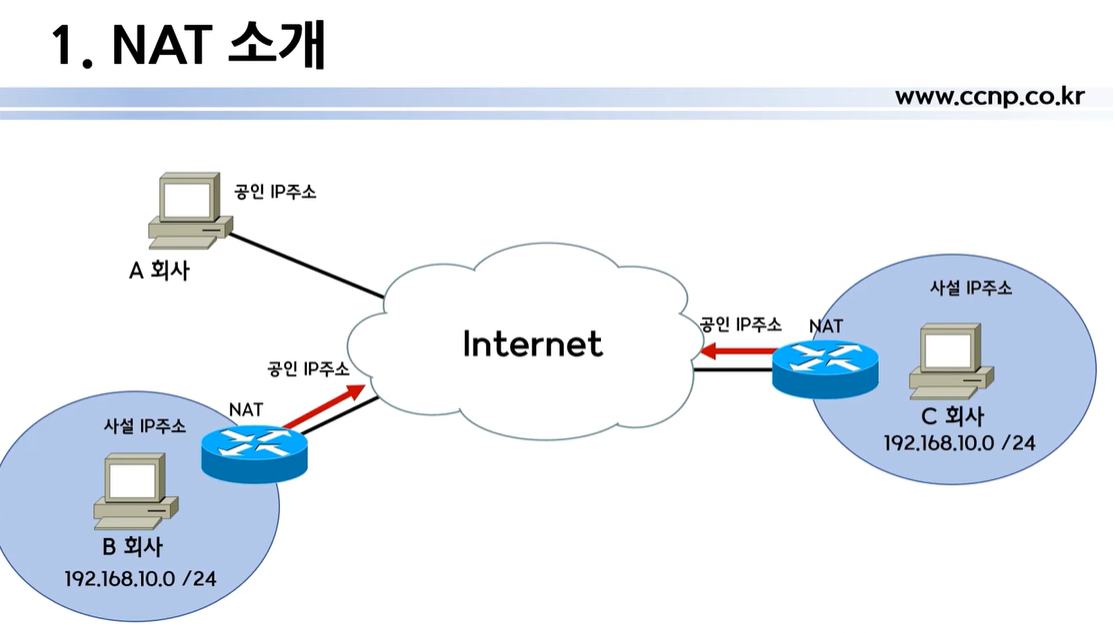
-NAT 개념
A 회사는 사내망 이용없이 바로 전세계가 공통으로 사용하는 공인 IP를 사용함(비용지불)
그러나 B회사, C회사는 사설 IP 주소로 내부에서만 사용하였으나, IP 주소가 동일해도 문제는 없었음
그러나, 전세계 인터넷이 확장되면서 인터넷 연결의 필요성이 대두되어, 공인 IP 연결이 필요했는데, 두 회사가 쫑나는 상황이 발생하여, 이를 해결하기 위해서 NAT가 개발 적용된 상황임
https://www.youtube.com/watch?v=Cjy5cDIaU_c

5. 활성화 함수 - 시그모이드, ReLu (94번 문제)
- 시그모이드 함수 : S자 로 이뤄진 함수이며, 0 으로 수렴하는 경우가 발생하기 때문에, 기울기 소멸현상이 발생함,
- ReLu 함수: 시그모이드의 기울기 소멸현상을 해결하기 위한 함수로, 간단한 함수임, 즉 0이하의 값을 없애기 위하여 0 이하의 case는 모두 0으로 출력하게 정의함
- 아래 영상은 재미삼아 공부 , GPT와 Transformer model에 대해 잘 설명됨
https://www.youtube.com/watch?v=wjZofJX0v4M
6. Spark 설명 (98번 문제) - 정답 : 1번
98. 인-메모리 방식으로 연산을 수행하는 Spark에 관 한 설명으로 가장 적절하지 않은 것은?
① 하둡2.0(YARN 환경)에서는 Spark를 지원하지 않는 다.
② 맵리듀스 연산에 비해 그 계산 속도가 매우 빠 르다,
③ 파이썬, 스칼라, 자바 언어를 사용하여 개발할 수 있다.
④ 기계학습, 그래프 연산 등 반복적인 계산 문제 를 해결하는 데 적합하다.

https://www.youtube.com/watch?v=D3TLh_QVGPg
-Spark : 머신러닝을 위해 라이브러리를 추가 해야 한다.
- Spark VS Hadoop
둘다 data 분석 엔진임
그러나 Spark는 in-memory에서 실행 -> 속도가 빠르다
2. Apache Spark
개요
- 출시 시기: 2010년에 UC 버클리에서 개발되었으며, 2013년에 아파치 재단의 오픈소스로 공개되었습니다.
- 목적: 실시간 데이터 처리와 속도에 중점을 둔 분산 처리 프레임워크로, Hadoop의 MapReduce를 대체하기 위해 개발되었습니다.
- 구성 요소:
- Spark Core: 기본적인 데이터 처리 및 분산 컴퓨팅 기능을 제공.
- Spark SQL: 데이터를 SQL 쿼리로 처리할 수 있는 기능.
- Spark Streaming: 실시간 데이터 스트림을 처리하는 기능.
- MLlib: 머신러닝 알고리즘을 제공하는 라이브러리[1][3][6].
특징
- 실시간 처리에 강점: 메모리 기반의 인메모리 캐싱을 사용하여 데이터를 빠르게 처리하며, 배치 처리보다 10배에서 최대 100배 빠른 속도를 제공합니다.
- 다양한 작업 지원: 배치 처리뿐만 아니라 스트리밍 데이터 처리, 머신러닝, 그래프 데이터베이스 등 다양한 작업을 지원합니다.
- 유연성: Hadoop의 HDFS 외에도 다양한 데이터 저장소(예: Amazon S3)와 통합할 수 있습니다[1][3][6].
cnn (합성곱 신경망)
- 재밌는 설명 : https://www.youtube.com/watch?v=ggBQj1NXUEg
'- 배움이 있는 삶 > - 시스템 구조' 카테고리의 다른 글
| 2021년 기출문제-시스템구조- 다시 (8) | 2025.03.25 |
|---|---|
| 2023년 기출문제- 시스템 구조 (3) | 2025.03.08 |
| 2020년 기출문제 - 시스템 구조 정리 (1) | 2025.02.19 |
| 2024년 기출문제 - 시스템구조 (2) | 2025.01.21 |
| 시스템 구조 - 기본과정 정리 (0) | 2024.10.26 |



