Microsoft 한석진님의 강의를 공부하고, 정리 합니다.
| Title | Link |
| ep 0 : 오프닝 | https://www.youtube.com/watch?v=DeOEuDosH2s |
| ep 1 : MLOps가 머길래 | https://www.youtube.com/watch?v=q2N6NZKxipg&t=25s |
| ep 2 : ML 생애주기(1) 데이타 준비 | https://www.youtube.com/watch?v=zyGYnYZaUEk |
| ep 3 : ML 생애주기(2) 실험/ 학습 | https://www.youtube.com/watch?v=ceGwH-sho2A&t=13s |
| ep 4 : ML 생애주기(3) 모델해석 | https://www.youtube.com/watch?v=LKk3bD8muhs |
| ep 5 : ML 생애주기(4) 배포/서빙 | https://www.youtube.com/watch?v=DMwMmTKA2bk |
| ep 6 : MLOps in Action 엿보기 | https://www.youtube.com/watch?v=HvfZO9uc_3g |
ep 0 : 오프닝
머신러닝하면, --> "모델 만들기" 하나의 활동이 전부 인 것처럼 인식된다, 그러나
- 데이타 가공에서 부터, 학습, 검증, 배포 등의 다양한 활동들이 고민이 되어야, 하나의 인공지능 서비스가 개발이 된다고 할 수 있다.
- MLOps 는 내가 만든 머신러닝 모델이 실제 프로젝트로 개발되어 서비스까지 가는데 도움이 되는 하나의 방법론/ tool 이라고 생각한다.
- 본 과정은 위의 table 처럼 6개의 episode로 구성되어 진행된다.
ep 1 : MLOps가 머길래
1) ML 생애주기
2) MLOps는 누가 하나 : Actors
3) 일반적인 DevOps와의 비교
4) 하면 뭐가 좋지?
5) MLOps 어디까지 가봤니?
1) ML 생애주기
-ML의 생명주기는 우리가 지속 공부했던, AI Lifecycle과 유사하며, 모델을 만들어서 배포하고 끝나는 것이 아니고, AI 서비스를 모니터링 하고 다시 ML을 upgrade 하기 위한 반복 loop를 진행되어야 인공지능의 서비스가 살아 있듯이 개선될 수 있다.

2) MLOps는 누가 하나 : Actors
본 강의에서는 MLOps의 actor를 크게 2 분류로 나누어 이야기 하고 있습니다.
- Data Scientist : 앞단에서 데이터의 탐색, 가공등 ML 생명주기의 전반부에 집중
- Data engineer / Software engineer : 배포, 운영 등 ML 생명주기의 후반부에 업무가 집중됨,

3) 일반적인 DevOps와의 비교
- DevOps
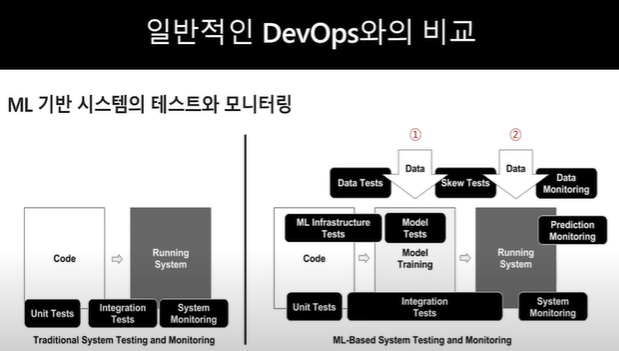
: 아래 그럼 처럼 일반적인 DevOps에서는 코드 개발 -> 운영 배포 가 이뤄지며 그와 동시에 각 수준별 Testing이 자동으로 이뤄지게끔 시스템을 구축함
- MLOps
: 전체적인 프로세스와 철학들은 DevOps와 동일하다고 할 수 있다.
: 아래 그림에서 DevOps 에서 진행하는 절차는 MLOps에서도 동일하다고 볼수 있지만, 크게 2 가지 차이점이 있다.
(1) Model Training 단계가 하나 더 있다.
- Model Training 을 위해 위에서 설명한 ML의 생명주기 활동이 추가로 필요하다
(2) Data가 필요하다
- DevOps에서는 SW code만 존재하면 됬었는데, MLOps를 위해서는 모델을 생성하거나, 모델이 잘 만들어졌는지 검증하기위한 Validation DB가 필요하다
* 강사님께서 설명은 맞으나, 아래 그림에 약간 오해가 있을 수 있어,
필자는 개발전략/요구사항 정의 -> ML 설계/개발 -> CODE 개발 -> 시스템 운영 하는 형태로 프로젝트가 진행된다고 보는 것이 일반적일 듯 함 (물론, 과제 방향성에 따라 동시에, 그 반대로도 가능은 할 듯)
4) 하면 뭐가 좋지?
-MLOps하는 목적 : 성공적으로 빠르고 안정적으로 인공지능 프로젝트를 수행하자 라는 것
-과거의 SW개발방법론처럼, 인공지능 ML의 Rapid Development 방법론이다

5) MLOps 어디까지 가봤니?
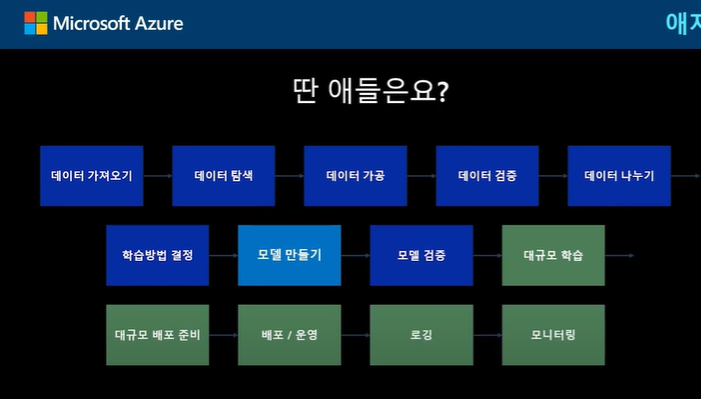
아래 그럼은 MS Azure에서 제공하는 MLOps Fraemwork 이며, MS Azure를 활용해 보면 도움이 될 듯 함. 본 과정에서는 각 내용에 대해 상세 다루지는 않고 있음

ep 2 : ML 생애주기(1) 데이타 준비
1) 문제/데이터 정의, 가설 수립
2) 데이터 이동 / 연계
- 데이터셋 공유 및 재사용 (DEMO)
3) 데이터 탐색/가공
- 데이터셋 및 주피터 노트북에서 탐색(DEMO)
- 데이터 레이블링(DEMO)
- Feature Importance 탐색(DEMO)
1) 문제/데이터 정의, 가설 수립
일반적인 모든 과제에서 "문제의 정의"는 매우 중요하고 시발점이 될 수 있다,
본 강의에서는 "문제/데이터 정의, 가설 수립" 을 위한 아래의 Framework을 제시 하고 있음
- 풀고자 하는 문제를 정의
- 그에 대한 가설을 정의
- 가설 정의 및 검증 위한 데이터 확보 방안
- 그에 대한 비즈니스 임펙트 및 고려사항 등을 정의 하도록 하고 있습니다

2) 데이터 이동 / 연계
- 데이터 이동 및 연계는 데이터를 준비하는 과정이다.
- 데이터를 다양한 곳에서 확보 및 수집하고, 그 다양한 곳에서 확보한 데이터 들을 연관된/ 우리가 필요한 데이터로 연결, 조정 하는 작업이 필요하고 이것을 연계라고 설명함

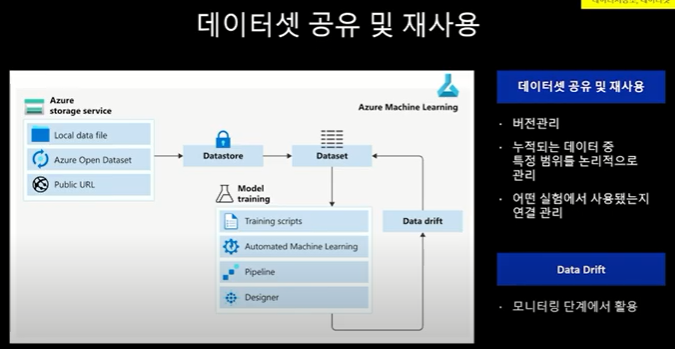
- 데이터셋 공유 및 재 사용
데이터를 수집하고, 연계 등의 과정에서는 데이터 셋의 공유 및 재 사용이 중요한 활동 중 하나이다.
이를 위해 MS Azure에서는 아래와 같은 절차의 기능들을 제공해 주며, 본 강의에서는 데모를 확인할 수 있다.
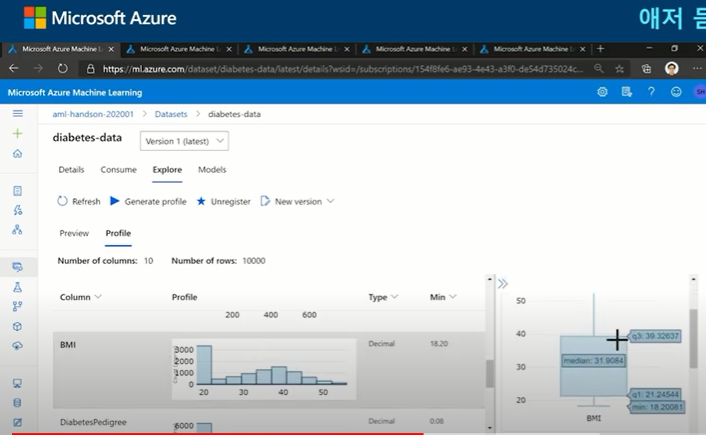
MS Azure에서는 아래와 같이 기존 data set에 대한 기본적인 버전관리, 통계정보 등을 쉽게 확인 할 수 있다고 함
3) 데이터 탐색 / 가공
- 데이터의 연계가 완료되었으며, 데이터의 탐색과정이 필요하겠죠. 당연히 우리가 확보한 데이터가 어떤 형태를 가지고 있고, 적절한 형태인지, 통계분포는 어떤지 등을 확인하는 과정이 탐색과정임
- 탐색이 어느 정도 됬다면, 데이터를 잘 사용하기 위한 가공 과정이 필요한 것임
(1) 데이터셋 및 주피터 노트북에서 탐색(DEMO)
- 확보한 데이터셋을 탐색하는 과정으로 일반적으로 python, R 등의 tool을 이용하여 아래와 같이 할 수 있다고 설명함
- MS Azure에서 보여지는 탐색 분석 기능에 대해서는 본 강의에서는 없었음(아마 기능을 제공 할 듯 함)

(2) 데이터 레이블링(DEMO)
데이터를 가공하는 부분중 하나가 레이블링 임
label을 정의해줘야, 우리가 모델을 만들 수 있으며, Azure에서도 아래와 같이 데이타를 label 할 수 있는 기능을 제공하고 있음 ( 블라우스, 스커트 인지 바로바로 label을 달 수가 있다고 함)
- 영상 labeling

- Text labeling
NAVER의 감성데이터 예로, Text data를 긍정/부정 등 감성으로 쉽게 labeling 할 수 있다고 함

(3) Feature Importance 탐색(DEMO)
- feature는 컬럼으로 어떤 컬럼이 우리에게 중요한지를 판단하는 활동임
- 우리가 확보한 데이터셋에서 어떤 feature들이 중요한지를 분석, 판단하기 위해 Azure에서는 아래와 같은 기능들을 제공한다고 함.

ep 3 : ML 생애주기(2) 실험/학습
1) 실험, 모델 학습/최적화/비교평가
2) 실험 추적관리
- 데이터셋, 코드, 환경, 모델, 서빙추적 (DEMO)
3) 자동화된 ML (Automated ML)
- 자동화된 ML 엿보기(DEMO)
4) 모델의 검증 : 예측성능, 처리성능
- 예측성능(DEMO)
- 처리성능(DEMO)
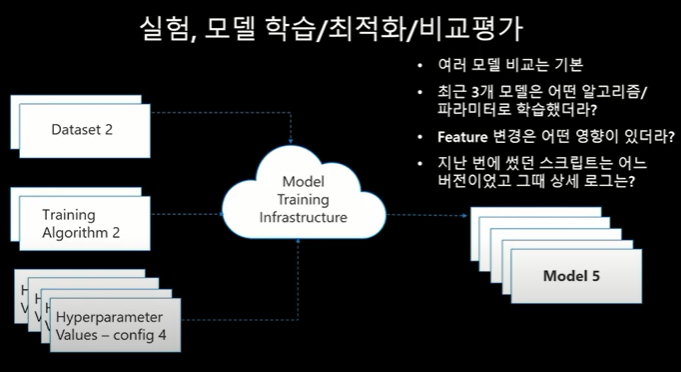
1) 실험, 모델 학습/최적화/비교평가
- 모델을 만들기 위해서는 크게 3가지가 필요하다, 1) DATA SET, 2) Algorithm, 3) Parameter value
위의 3가지로 모델을 만든다.
- 최적의 모델을 만들기 위해서 우리는 각각의 값들을 바꿔가면서 실험을 하게 되며, 이는 실험의 수가 너무 많아질 수 있어, 어떻게 하면, 최적화 실험을 할 수 있을까를 고민하게 된다.
-최적의 모델을 선정하기 위해 비교평가(BMT)가 필요하며, 비교평가를 통해서 최적의 모델을 선정하게 된다
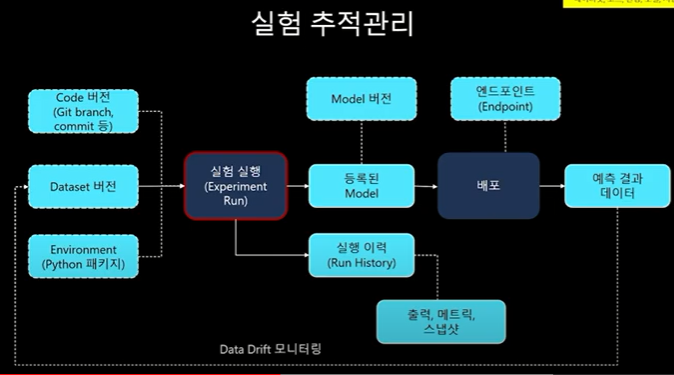
2) 실험 추적 관리
- 위와 같이 다양한 실험들을 진행해야 되기 때문에, 복잡한 변수들에 의한 실험이며, 이를 위해 실험의 추적관리가 필요하다
- 어떤 버전, 어떤 데이터셋, 패키지 버전, 실험환경, 도메인 등 , 다양한 모델의 추적관리가 필요하다
이를 위해 Azure에서는 아래 process에 따른 추적관리가 가능하도록 되어 있다.
- 데이터셋, 코드, 환경, 모델, 서빙추적 (DEMO)
아래는 Azure의 모델 관리 화면이다.
아래 dot chart는 각 여러 모델들의 성능별로 display 하고 있으며, 그 아래에서는 list 형태로 모델들이 정리가 되고, 모델의 상세 정보들, 릴리즈 정보 등도 관리가 될 수 있다.

3) 자동화된 ML
- MS는 모델생성을 위한 입력값의 정의에 따라 모델의 성능이 어떻게 될 것이다라고 예측할 수 있도록 모델 파이프라인을 정의 했음
- 이렇게 함으로써, 다양한 모델 생성 실험을 모두 하지 않아도 되어, 최적의 모델을 빠르게 생성 할 수 있게 하였음
- 다양한 모델 생성은 Azure에서 user의 input data ( dataset, algorithm, parameter 등)을 입력하면, 그에 따라 자동 모델 성능이 예측된다고 함
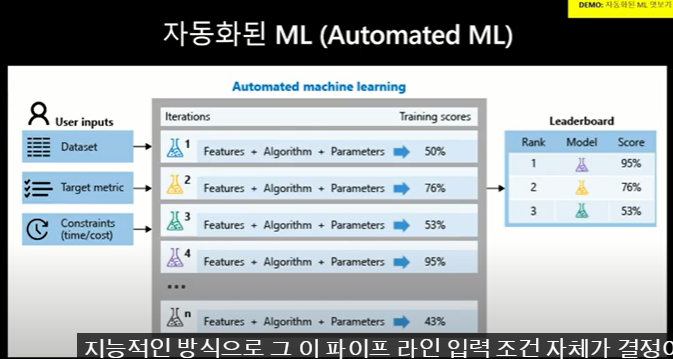
- 각 input에 따라 여러 알고리즘들의 성능이 평가되고, 생성된 모델 중 가장 좋은 모델이 도출됨
각 모델의 성능 지표들에 대해서도 azure에서는 확인이 가능하며, 모델을 만드는 과정에서의 상세 log data도 확인 할 수 있다고 함

4) 모델의 검증 : 예측성능, 처리성능
모델의 검증은 크게 2가지로 구분될수 있다
- 예측성능 : 모델이 얼마나 실제 환경에서 정확하게 실제값과 가깝게 설명하고 있는가?
- 처리성능 : 모델이 얼마나 안정적이고 빠르게 처리 하고 있는가?

(1) 예측성능(DEMO)
예측성능은 모델의 정확도 등에 대한 성능으로, 분류모델, 회귀모델 이냐에 따라 각각의 방식으로 예측 정확도를 측정 한수 있다.

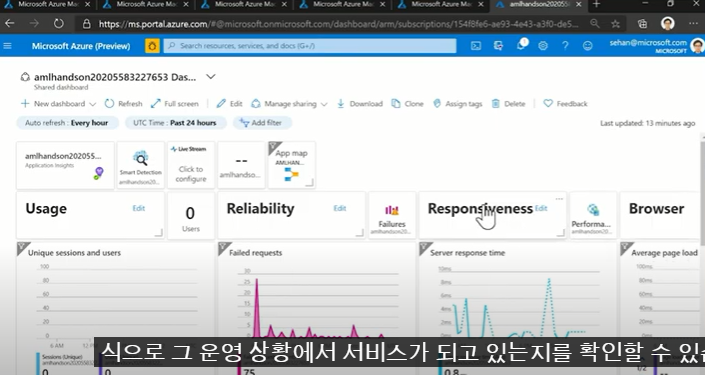
(2) 처리성능(DEMO)
처리 성능은 모델을 개발하는 담당자는 많이 고려 안할 수도 있음
오히려, SW 공학/ 인프라를 담당하는 사람들이 더 고민할 수 있음 (서비스가 배포되고 얼마나 안정적으로 활용되고 있는지를 확인하기 위한 성능)
- Azure에서는, 배포되어 있는 서비스가, 어떤 이슈들이 있는지를 통합관리할 수 있다고 함
- 서비스되고 있는 모델의 처리 성능을 dashboard 형태로 display 해주고 있음
ep 4 : ML 생애주기(3) : 모델 해석
1) 모델 해석이 왜 중요한가
2) 모델을 해석하려는 시도
3) azureml.interpret 들여다보기
4) Explainer 관련 시각화 예시
- azure머신러닝에서 모델해석(DEMO)
모델 해석은 ML 생애주기상에 "모델 검증" 활동에 해당한다.
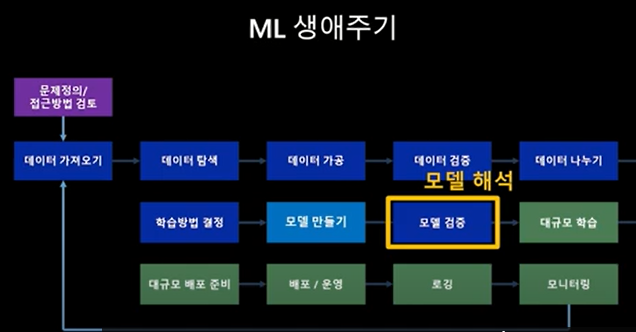
1) 모델해석이 왜 중요한가?
- 모델 해석 활동은 ML생애주기에서 "모델 검증" 활동에 해당한다
- 성능이 괜찮은 거 같은데 -> 해석이 잘못되면, 인류에게 치명적인 오류가 발생할 수도 있다
- 단순히 모델의 Accuracy, f-1 score 가 높다고 좋은 모델이 아니고, 그 모델을 사람이 해석할 수 있어야 한다. 이를 human-in-loop 이라고도 하며, 특정한 경우에서는 사람이 직접 판단 및 해석이 필요 할 수 있다.
2) 모델을 해석하려는 시도
- 모델 해석 Framework을 제시하고 있으며, 가로축에는 "Global - Local"로 구분하고, 세로축에는 "Specific - Agnostic"으로 구분하여 해석할 수 있다고 제시 하고 있음

3) azureml.interpret 들여다보기
- azure에서 모델을 해석할 수 있는 일부 기능이 있다고만 소개 하고 있네요. 실제 tool을 사용해 봐야 알 수 있을 듯 합니다.
4) Explainer 관련 시각화 예시
- azure머신러닝에서 모델해석(DEMO)
azure에서 모델을 해석하라 고 하면, 아래와 같이 해석한 결과를 보여 준다.

- Perturbation 탐색
: 나이가 변동됨에 따라 어떤 변수들이 영향이 있는지 등을 분석 해석하기 위한 기법이라고 함

본 강좌에서는 아마 초급과정으로 모델에 대한 다양한 해석기법들에 대해서 심도있게 다루지는 못하고, 간단히 보여주는 정도로 끝나고 있다.
ep 5 : ML 생애주기(4) 배포/서빙
1) azure 머신러닝에서 패키징, 배포(서빙) 개념
- 자동화된 ML에서의 No-code 배포(DEMO)
2) 모델의 모니터링: 데이터 드리프트(Data Drift)
- azure 머신러닝에서 데이터 드리프트 확인(DEMO)
배포/ 서빙은 ML 생애주기의 마지막 단계 이다

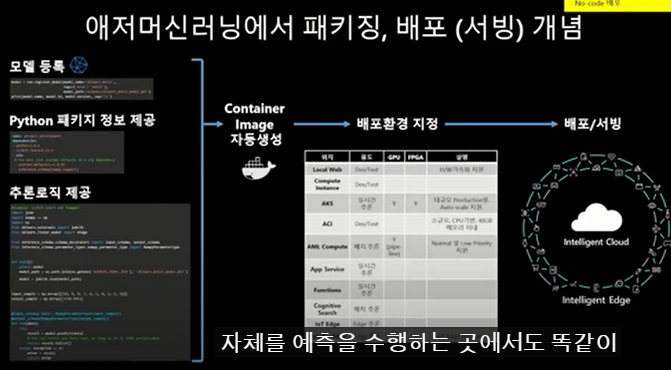
1) azure 머신러닝에서 패키징, 배포(서빙) 개념
(1). 모델 등록 : 이전 단계에서 만들어진 모델을 최종 선택하여, 서비스화 시키기 위해 모델을 등록하게 됨
(2). 파이선 패키지 정보 : 어떤 파이선패키지를 이용하여 로직을 실행할 것인지에 대한 정보가 필요함
(3). 추론로직 제공 : 데이터를 어떻게 가져오고, 어떤식으로 예측값을 계산해 내고 하는지에 대한 정보를 제공하는 것이 추론로직임
- 위의 3가지 정보를 제공해 주고 이제 다음 단계로 진행해라 라고 명령을 하게 되면,
(4) Container Image 자동 생성 : command에 따라 image 자동생성됨
(5) (6) 배포 환경등을 지정해 주면 자동으로 배포까지 완료될 수 있다
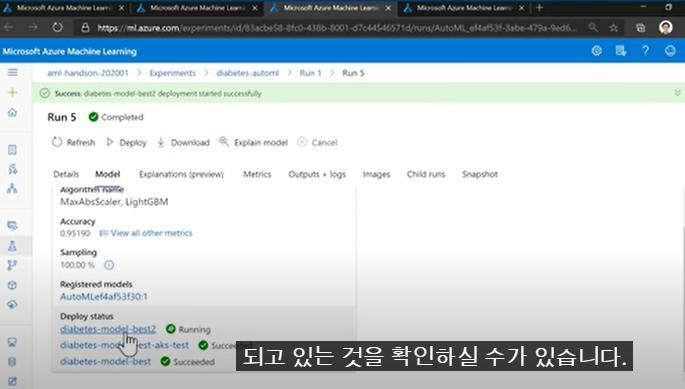
- 자동화된 ML에서의 No-code 배포(DEMO)
(1) azure에서 최적의 model을 선택하고, 마우스의 "Deploy" 배포버튼을 오른쪽에 배포환경정보를 입력하고 오른쪽 하단의 deploy(지금은 짤림)을 누르면, 바로 배포가 됨
- No-code 배포인 이유 : automated ML은 필요한 요소들, 데이터스키마등을 이미 azure에서 선택하여 setting 한 상태이기 때문에, 별도의 정보 없이 바로 deploy 할 수 있는 것임

배포가 되고 있는 화면임.
Deploy status를 보면, 현재 배포되고 있는 모델에 대해 running으로 표시되면, 클릭하면, 상세 정보등을 확인할 수 있다
2) 모델의 모니터링: 데이터 드리프트(Data Drift)
- azure 머신러닝에서 데이터 드리프트 확인(DEMO)
- data drift : 모델의 성능을 모니터링 하기 위한 방법 중 하나임. 모델의 예측성능을 파악할려면, 실제값과 예측값이 있어야 하는데, 예측값을 바로확인하기 어려워, 예측성능을 바로 확인하기가 어려움
따라서, data drift는 내가 학습할때 사용했던 데이터셋의 pattern 과 운영에서 수집되는 데이터셋의 pattern을 비교해 보는 것임
예로) a 환경하에서의 데이타를 바탕으로 모델을 만들었는데, 운영하면서 모델이 변화가 일어나고 성능이 저하가 발생할 수 있음, 이러한 상황을 미리 data drift를 이용하여 파악할 수 있다고 함
- azure에서 drift를 하도록 세팅해 주면,
모델을 생성시의 data set에 의한 성능과, 운영하면서 발생하는 모델의 성능에 대한 지표를 dashboard 형태로 관리해 준다
(a) Drift magnitude : 2개의 data set에 78%로 drift가 존재한다.
(b) Threshold : 해당 threshold를 넘어서면, 나에게 alert를 주거나, 다른 piepeline을 진행 시킬수 있다
제 공부한 느낌한 drift는 모델생성시와 운영시의 gap을 분석하여, 문제점을 파악하고 개선하기 위한 분석 활동이라고 이해됩니다.

ep 6 : MLOps in Action 엿보기
1) 이제껏 알아본 것들이 실제 어떻게 구현되나
- azure ML 과 azure DevOps와의 만남(DEMO)
2) MLOps란 무엇이고 어떻게 준비할 수 있는가
아래 azure 구독부분만 연결해서 바로 돌려 볼수 있다고 함
https://azuredevopsdemogenerator.azurewebsites.net/?name=azure%20machine%20learning
Azure DevOps Demo Generator
Azure DevOps Demo Generator helps you create projects on your Azure DevOps organization with pre-populated sample content that includes source code, work items, iterations, service endpoints, build and release definitions based on a template you choose.
azuredevopsdemogenerator.azurewebsites.net
(1) 위의 site에 들어가면, create할 수 있으며, choose template를 클릭하여 template를 선택한다
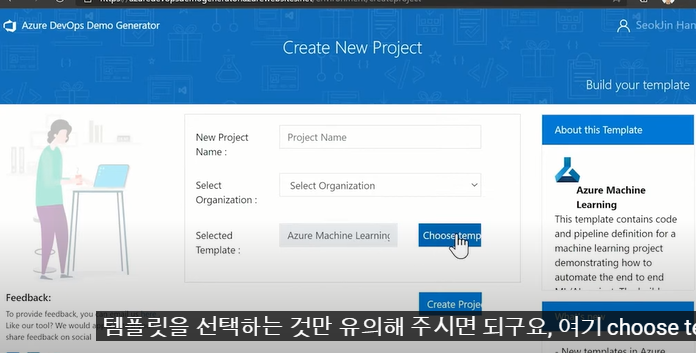
(2) azure machine learing 선택
- 메뉴 : DevOps Lab 선택
- 오른쪽 하단의 azure machine Learing 선택
- 다시 위 화면으로 복귀 -> Create Project 클릭하여 새로운 프로젝트 생성하면됨

(3) 프로젝트 생성된 화면
아래와 같은 프로젝트가 생성된 화면을 확인 할 수 있음
- 아래는 각 pipeline에 따라 진행하면 됨

(4) pipeline 생성됨
아래 그림처럼 왼쪽 메뉴에서 pipeline을 선택한다.

우리가 구성한 pipeline을 확인 할 수 있고, 이전에 episode에서 설명한 내용들을 볼 수 있다.

pipeline에 따라 모델이 생성되고, 새로운 모델의 성능이 평가되고, 통합테스트까지 자동으로 진행되면,
새롭게 생성된 모델의 성능이 더 우수하다면, 아래 이미지의 맨 오른쪽 diagram에서 최종 배포를 할 수 있다
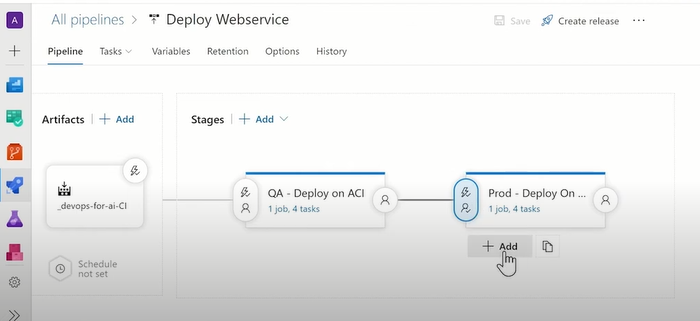
실제 어떻게 구현되나 - 고급버전
- https://github.com/Microsoft/MLOpsPython
GitHub - microsoft/MLOpsPython: MLOps using Azure ML Services and Azure DevOps
MLOps using Azure ML Services and Azure DevOps. Contribute to microsoft/MLOpsPython development by creating an account on GitHub.
github.com
위의 github에서 template 자료 확인 가능함
고급버전 azure ML pipeline 화면
- IaC -> azure 여러 자원들을 자동으로 생성해주는 pipeline임
-mlops -> mlops pipeline이 존재함 => 이를 클릭하고 들어감
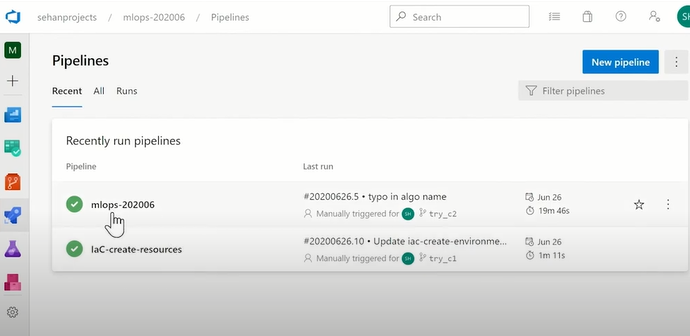
2) MLOps란 무엇이고 어떻게 준비할 수 있는가
- 가능한 이유는 ML 생애주기에 따라 각 산출물들이 추적관리가 가능하기 때문에, 각 산출물들을 pipeline으로 묶어서 처리 할 수 있다는 개념에서 출발한다.
여기까지, MS의 Azure를 활용한 MLOps에 대하 알아보았습니다. 본 자료는 기본 개념에 대한 자료로서 좀더 심도있는 연구와 직접 사용해 보면 더욱 재밌을 듯 합니다.
'- 배움이 있는 삶 > - AI | Big data' 카테고리의 다른 글
| [python] 구구단의 배수 제외하여 리스트 객체에 저장 (0) | 2024.08.21 |
|---|---|
| [6/14] Anaconda에서 python library 설치하기 (0) | 2024.08.20 |
| AI Prompt Engineering (2) | 2024.08.20 |
| [Python] 가위,바위,보 게임 (0) | 2024.08.20 |
| Apple WWDC 2024 Summary (1) | 2024.06.12 |



