- 교육 및 Syllabus : https://www.sten.or.kr/bbs/board.php?bo_table=istqb_lib&wr_id=211
ISTQB > ISTQB 자료실 > KSTQB & CSTQB AI Testing(AIT) 실라버스
KSTQB는 중국 CSTQB와 함께 AI 테스팅에 관한 실라버스를 준비하였습니다. 자율시스템 등 4차산업의 발전으로 인해 그 분야가 계속 확장되고 있어 AI 기반 시스템에 대한 테스팅이 날로 중요해지고
www.sten.or.kr
- 이미 번역해 놓은 자료가 있음: 중소SW기업 SW품질관리 가이드-Ai 시스템 테스트
: http://www.kstqb.org/board_skin/board_list.asp?bbs_code=11
KSTQB
About KSTQB KSTQB 주관 자격 시험 자격증 활용 현황 시험 안내 및 일정 학습 자료실 News & Events 실러버스(Syllabi) 샘플 문제 참고 도서 참고 자료
www.kstqb.org
Table Contents
- Chapter 1: Introduction to AI and Testing - 150 minutes
- Chapter 2: AI System Characteristics and Acceptance Criteria – 120 minutes
- Chapter 3: Machine Learning – 180 minutes
- Chapter 4: Machine Learning Performance Metrics and Benchmarks – 90 minutes
- Chapter 5: Introduction to the Testing of AI Systems – 45 minutes
- Chapter 6: Black Box Testing of AI-Based Systems – 120 minutes
- Chapter 7: White Box Testing of Neural Networks – 45 minutes
- Chapter 8: Test Environments for AI-Based Systems – 45 minutes
- Chapter 9: Using AI for Testing - 30 minutes
Chapter 1: Introduction to AI and Testing
- 1.1 DEFINITION OF ‘ARTIFICIAL INTELLIGENCE’ AND THE ‘AI EFFECT’
- AI Definition
a branch of computer science devoted to developing data processing systems that perform functions normally associated with human intelligence, such as reasoning, learning, and self-improvement (ISO/IEC 2382:2015, Information technology -- Vocabulary) - AI Effect
people’s understanding of what is meant by AI changes over time – this is often known as the ‘AI Effect’.- 영향/ 효과 : 영향이라기 보단, AI의 의미가 시간이 지남에 따라 계속 변화한다라는 내용을 그렇게 부른다고 함
- AI Definition
- 1.2 AI USE CASES
- AI can be used for a wide variety of application areas
- A comprehensive list of AI use cases can be found at https://appliedai.com/use-cases/.
appliedAI
Find latest AI & IoT products and solutions across all industries and functions. Discover and connect with leading edge startups and solutions providers.
appliedai.com
- 1.3 AI USAGE AND MARKET
- (Old version marktet estimation). AI market will increase popularly in the future, Just only that's it
- 1.4 FAILURES AND THE IMPORTANCE OF TESTING FOR AI-BASED SYSTEMS
- There have already been a number of widely publicized failures of AI.
- According to a 2019 IDC Survey, “Most organizations reported some failures among their AI projects with a quarter of them reporting up to 50% failure rate; lack of skilled staff and unrealistic expectations were identified as the top reasons for failure.”
- [https://www.idc.com/getdoc.jsp?containerId=prUS45344519]
- 1.5 THE TURING TEST AND THE HISTORY OF AI
- AI is often considered to have started in the 1950s. 1950 saw Alan Turing publish his paper on Machine Intelligence including what is now known as the ‘Turing Test’. In 1951, in the UK,
- 1.6 ROBOTS AND SOFTWARE AGENTS
- 일반적인 robot과 software agent에 대한 간략한 소개 정도
- 1.7 AI TECHNOLOGIES
- [ISO SC42]:
- Search algorithms
- Reasoning techniques
- Logic programs
- Rule engines
- Deductive classifier
- Case-based reasoning
- Procedural reasoning
- Machine learning techniques (see section 3 for more detail)
- Artificial neural networks (Feed forward neural networks • Recurrent neural networks)
- Bayesian network
- Decision tree
- Deep learning(Convolutional neural networks)
- Reinforcement learning
- Transfer learning
- Genetic algorithms
- Support vector machine
- 1.8 AI HARDWARE
- NVIDIA, Google, Intel, Apple, Huawei 등을 소개함
- 1.9 AI DEVELOPMENT FRAMEWORKS
- • TensorFlow – based on data flow graphs for scalable machine learning by Google
• PyTorch - neural networks for deep learning in the Python language
• MxNet – a deep learning open-source framework used by Amazon for AWS
• Caffe/Caffe2 - open frameworks for deep learning, written in C++ with a Python interface
• CNTK – the Microsoft Cognitive Toolkit (CNTK), an open source deep-learning toolkit
• Keras - a high-level API, written in the Python language, capable of running on top of TensorFlow or CNTK
- • TensorFlow – based on data flow graphs for scalable machine learning by Google
- 1.10 NARROW VS GENERAL AI AND TECHNOLOGICAL SINGULARITY
- 1.11 AI AND AUTONOMOUS SYSTEMS
- 1.12 SAFETY-RELATED AI-BASED SYSTEMS
- 1.13 STANDARDIZATION AND AI
- 1.10 ~ 1.13 까지 일반적인 애기 임
- 1.14 THE AI QUALITY METAMODEL – DIN SPEC 92001:2019
- AI 품질 메타 모델을 무료로 사용할 수 있다고 되있는데, 대부분 유료로 되 있음
- DIN SPEC 92001- 1 is a freely available standard that provides an AI Quality Metamodel intended to ensure the quality of AI-Based systems. The standard defines a generic life cycle for an AI module, and assumes the use of ISO 12207 life cycle processes
- DIN SPEC 92001-2 describes quality requirements which are linked to the three quality pillars of
- functionality & performance (기능/성능)
- robustness (견고성)
- comprehensibility(이해용이성)
Chapter 2: AI SYSTEM CHARACTERISTICS AND ACCEPTANCE CRITERIA
- ISO 25010 일반적 품질 특성을 바탕으로 AI 품질 특성을 정의 할 수 있다.

- 2.1 AI-SPECIFIC CHARACTERISTICS
| CHARACTERISTICS | Descriptions |
| 2.1.1 Adaptability(적응성) | Adaptability is the ability of the system to react to changes in the environment in order to continue to meet both functional and non-functional requirements. |
| 2.1.2 Autonomy(자치성) | Autonomy is the ability of the system to work for sustained periods without human intervention. |
| 2.1.3 Evolution(진화) | Evolution is concerned with the ability of the system to cope with two types of change. |
| 2.1.4 Flexibility(유연성) | Flexibility is the ability of a system to work in contexts outside its initial specification |
| 2.1.5 Bias(편견) | Bias (also known as unfairness) is a measure of the distance between the predicted values provided by the machine learning model and the actual values |
| 2.1.6 Performance Metrics | the most popular of which are accuracy, precision and recall (see section 4 for more details). These metrics should be agreed and defined as part of the system requirements |
| 2.1.7 Transparency(투명성) | Transparency (also known as explainability) is a measure of how easy it is to see how an AI-Based system came up with its result. - 어떻게 결과가 도출되었는지 쉽게 판단할 수 있어야 함 : 고양이 식별시 바로 인지 할 수 있도록 For instance, an image classifier that determines an object is a cat could demonstrate transparency by pointing out those features in the input image that made it decide the object was a cat. |
| 2.1.8 Complexity(복잡성) | AI-Based systems are often used for problems where there is no alternative, due to the complex nature of the problem (e.g. making decisions based on big data). |
| 2.1.9 Non-Determinism(비결정성) | A non-deterministic system is not guaranteed to produce the same outputs from the same inputs every time it runs (in contrast to a deterministic system). -동일한 입력시 다른 결과가 발생한다. |
- 2.2 ALIGNING AI-BASED SYSTEMS WITH HUMAN VALUES
- Russell [Myths of AI] points out two major problems with AI-Based systems.
- First, the specified functionality may not be perfectly aligned with the values of the human race, which are (at best) very difficult to pin down, (pin down : 강요하다, 분명히 정의하다, bind, hold, force, define)
- --> 그 이유는 AI가 학습을 위해서는 인간을 관찰(Observation) 해야 하고, 장시간 이뤄져야 하는데, 인간의 behaviour는 계속 변화하고 있고, 최근에는 빠르게 변화하고 있기 때문이라고 설명함
- ?? AI가 인간을 따라 잡을수 있을까?
- Second problem is that any sufficiently capable intelligent system will prefer to ensure its own continued existence and to acquire physical and computational resources – not for their own sake, but to succeed in its assigned task : 인공지능이 그들 스스를 위한 것이 아니라, 할당된 업무를 수행하는 것을 선호한다.-> 정말?
- 예전 생각으로 이해됨 - 궁극적으로 AI는 인간처럼 그들 스스로를 위하는 행동을 할 것인가?
- 인간이 과연 그것을 허락 할 것인가?
- First, the specified functionality may not be perfectly aligned with the values of the human race, which are (at best) very difficult to pin down, (pin down : 강요하다, 분명히 정의하다, bind, hold, force, define)
- Russell [Myths of AI] points out two major problems with AI-Based systems.
- 2.3 SIDE-EFFECTS
- Side-effects occur when an AI-Based system attempts to achieve its objectives and causes (typically negative) impacts on its environment
- 2.4 REWARD HACKING
- AI-Based systems using reinforcement learning (see section 3.1) are based on a reward function that gives the system a higher score when the system better achieves its objectives.
- Reward hacking occurs when the AIBased system satisfies the reward function and so gets a high score, but mis-interprets the required objective
- 2.5 SPECIFYING ETHICAL REQUIREMENTS FOR AI-BASED SYSTEMS
- The European Commission High-Level Expert Group on Artificial Intelligence published key guidance to promote trustworthy AI in the area of ethics in April 2019
- 인간의 자치, 피해를 막고, 공정성, 설명성 측면의 원칙을 준수하며, AI를 개발해야 한다
- 어린이, 장애인 등을 다양하고 취약한 그룹들에 더 주의를 기울여야 한다
- 사회, 개인에에게 지속가능한 이득을 가져와야 한다
- The European Commission High-Level Expert Group on Artificial Intelligence published key guidance to promote trustworthy AI in the area of ethics in April 2019
Chapter 3 MACHINE LEARNING
- 3.1 INTRODUCTION TO MACHINE LEARNING
- ML : AI의 한 형태이다,
- 이는 where the AI-Based system learns its behaviour from provided training data, rather than being explicitly programmed
- The outcome of ML is known as a model,
- which is created by the AI development framework using a selected algorithm and the training data
- ML : AI의 한 형태이다,
- 3.2 THE MACHINE LEARNING WORKFLOW
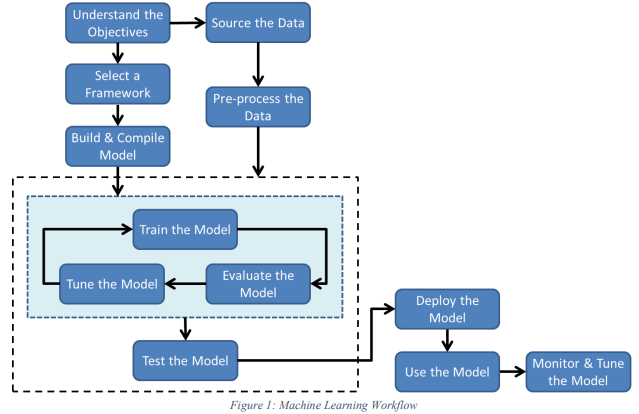
- 위 그림에서 build&compile model --> train and tune model을 하는 것으로 됨
- 이는 모델이 python과 같은 SW Code안에 있기 때문에, 그 code를 compile 한다는 의미로 해석됨.
Wikipidia 출처 :
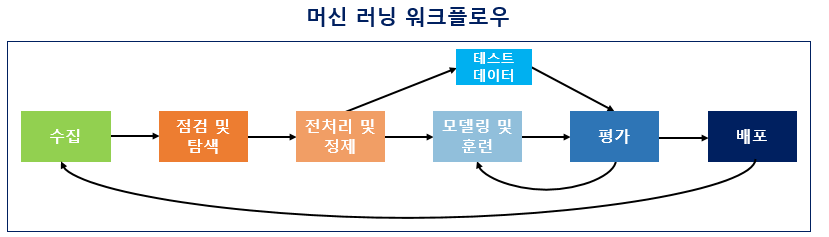
- 3.4 OVERFITTING AND UNDERFITTING IN MACHINE LEARNING
- 3.4.1 Overfitting
- Overfitting occurs when the model learns incorrect relationships from extraneous information,
- such as insignificant details, random fluctuations and noise in the training data (i.e. too many features have been included in the training data) - Training data에
- Overfitting occurs when the model learns incorrect relationships from extraneous information,
- 3.4.2 Underfitting
- Underfitting occurs when the model is unable to identify the relationships between inputs and outputs from the training data.
- Underfitting usually occurs when there is insufficient training data to provide enough information to derive the correct relationships between inputs and outputs
(i.e. not enough features included in the training data),
- Underfitting occurs when the model is unable to identify the relationships between inputs and outputs from the training data.
- 3.4.1 Overfitting
- 3.5 BIAS AND FAIRNESS IN THE TRAINING DATA
- 데이타에는 성별, 나이, 지역, 나라, 교육정도, 수입, 주소 등에 따라 편차가 있다고 정도 소개
- 3.6 DATA QUALITY
- Supervised learning assumes that the training data is correct. However, in practice, it is rare for training data sets to be labelled correctly 100% of the time. 의 내용
- 3.7 MACHINE LEARNING ALGORITHM/MODEL SELECTION
- the model settings and hyperparameters is a science or an art.
- There is no definitive approach that would allow the selection of the optimal set purely from an analysis of the problem situation
- in practice this selection is nearly always partly by trial and error
- 3.8 MACHINE LEARNING TESTING AND QUALITY ASSURANCE
- 3.8.1 Review of ML Workflow
- The ML workflow that is used should be documented
- 3.8.2 Acceptance Criteria
- Acceptance criteria (including both functional and non-functional requirements) should be documented and justified for use on this application.
- 3.8.3 Framework, Algorithm/Model and Parameter Selection
- 문서화해야 한다고 함
- 3.8.4 Model Updates
- Whenever the deployed model is updated it should be re-tested to ensure it continues to satisfy the acceptance criteria,
- 3.8.5 Training Data Quality : 별 애기 없음
- 3.8.6 Test Data Quality
- Test data should be systematically selected and/or created and should also include negative tests
- 3.8.7 Model Integration Testing
- 일반적 Integration Testing 와 같은 개념을 설명함,
- 3.8.8 Adversarial Examples and Testing (적대적인 예제와 테스팅)
- 예로, AI가 사람이 인식하는 것과 다르게 인식할 것을 고려하여 Testing 해야 한다는 내용
- 3.8.1 Review of ML Workflow
Chapter 4 MACHINE LEARNING PERFORMANCE METRICS AND BENCHMARKS


- 4.1 MACHINE LEARNING PERFORMANCE METRICS
- 4.1.1 Confusion Matrix : 아래 4가지 confusion matrix를 소개함
- 4.1.2 Accuracy : Accuracy measures the proportion of all classifications that were correct
- 전체 결과 중에, 참/ 거짓을 제대로 인식한것
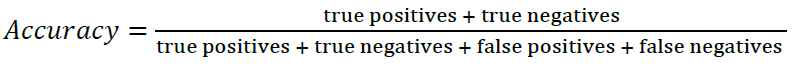
- 4.1.3 Precision
Precision measures the proportion of predicted positives that were correct (how sure you are of your predicted positives)
-참이라고 인식한 것중 진짜 참인 것

- 4.1.4 Recall
Recall (or Sensitivity) measures the proportion of actual positives that were predicted correctly (how sure you have not missed any positives)
- 실제 참 중에 참이라고 인식 한것

- 4.1.5 F1-Score
The F1-Score provides a balance (the harmonic average) between Recall and Precision

- 4.2 BENCHMARKS FOR MACHINE LEARNING
- 전문가들은 New ML system을 평가하기 위해서 BMT를 선호하나, 매우 비싸다, 그래서 BMT Suites를 사용하고 한다. 예로 )
- MLPerf : SW Framework을 위한 BMT 를 제공함 - 글로벌 인공지능 반도체 성능 테스트(벤치마크) 대회인 ‘엠엘퍼프(MLPerf)
출처 : 아이티데일리(http://www.itdaily.kr)- https://byline.network/2021/12/13-171/
- https://cloud.google.com/blog/ko/products/ai-machine-learning/google-breaks-ai-performance-records-in-mlperf-with-worlds-fastest-training-supercomputer
- DAWNBench : benchmark suite from Stanford University: 딥 러닝의 추론과 학습을 테스트하는 벤치마크임
DAWNBench: 딥 러닝 벤치마크 - 컴퓨터 / 하드웨어 - 기글하드웨어 : https://gigglehd.com/gg/?mid=hard&document_srl=2850684.
- MLPerf : SW Framework을 위한 BMT 를 제공함 - 글로벌 인공지능 반도체 성능 테스트(벤치마크) 대회인 ‘엠엘퍼프(MLPerf)
- 전문가들은 New ML system을 평가하기 위해서 BMT를 선호하나, 매우 비싸다, 그래서 BMT Suites를 사용하고 한다. 예로 )
Stanford DAWN Deep Learning Benchmark (DAWNBench) ·
DAWNBench is a benchmark suite for end-to-end deep learning training and inference. Computation time and cost are critical resources in building deep models, yet many existing benchmarks focus solely on model accuracy. DAWNBench provides a reference set of
dawn.cs.stanford.edu
Chapter 5 INTRODUCTION TO THE TESTING OF AI SYSTEMS
- 5.1 CHALLENGES IN TESTING AI-BASED SYSTEMS
- AI 기반 시스템이라도 conventional components로 구성되어 있기 때문에, 기본적인 SW Testing 접근법이 요구됨
- 5.1.1 System Specifications
- AI 시스템은 비정형화 되어 있어, 종종 Tester가 비정형 예상결과를 결정해야 될때도 있다
- 5.1.2 Test Input Data
- Input data는 형태가 다양하며, big data일 수 있기 때문에, Input data 관리는 Data Scientist가 test data를 관리 하기도 하며, Tester가 수행하기도 한다.
- 5.1.3 Probabilistic & Non-Deterministic Systems
- 많은 AI 시스템은 확률론적 성질을 가지고 있기 때문에, 예상결과도 정형화되어 있지 않다, 따라서, TE는 허용오차(Tolerance) 등을 포함하여, 더욱더 정교한 예상결과(expected result)를 만들어 내야 한다.
- 5.1.4 Self-Learning Systems
- AI가 스스로 학습하기 때문에, 과거의 경험과 방법이 더이상 타당하지 않을 수 있다. 이러한 것은 TE들에게 더 많은 도전과 어려움을 주고 있다
- 5.1.5 Complexity
- 별 내용 없음
- 5.1.6 AI-Specific Characteristics (see section 2.1)
- 5.2 THE TEST ORACLE PROBLEM FOR AI-BASED SYSTEMS
- AI 시스템을 테스트 할때 되풀이되는(recurring) 문제는 Test oracle 문제이다.
- Poor specifications, complex, probabilistic, self-learning and non-deterministic systems make the generation of expected results problematic.
- AI 시스템을 테스트 할때 되풀이되는(recurring) 문제는 Test oracle 문제이다.
Ch 6 BLACK BOX TESTING OF AI-BASED SYSTEMS
- 6.1 COMBINATORIAL TESTING
- Goal : Understand how pairwise testing is used for AI-Based systems
- ISO/IEC/IEEE 29119- defines several combinatorial testing techniques,
- All Combinations, Each Choice Testing, Base Choice Testing and Pairwise Testing
- In practice pairwise testing is the most widely used
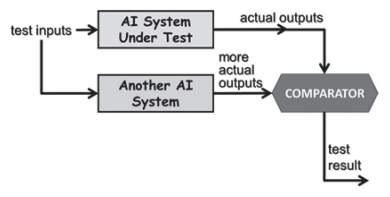
- 6.2 BACK-TO-BACK TESTING
- an alternative version of the system is used as a pseudo-oracle to generate expected results for comparison from the same test inputs.
- 즉, 다른 버전의 시스템에 같은 테스트 input으로 그 결과를 비교하는 검증 법
- A 의 결과와 B의 결과를 비교하여, 같으면 Pass, 다르면 fail로 정의 함
- This is sometimes known as differential testing.
- alternative version : e.g. already existing, developed by a different team or implemented using a different programming language
중소SW기업 SW품질관리 가이드-Ai 시스템 테스트 : http://www.kstqb.org/board_skin/board_list.asp?bbs_code=11
AI 기반 정보시스템의 주요 블랙박스 테스팅 기법
I. AI 기반 정보시스템의 고유특성으로 인한 테스팅 기법의 필요성 - AI 기반 정보시스템의 고유특성으로 인해 시스템 명세 문제, 테스트 입력 데이터 문제, 비결정적 시스템 문제, 복잡한 심층신
itpenote.tistory.com
6.3 A/B Testing
- A/B testing is a statistical testing approach that allows testers to determine which of two systems performs better
- it is sometimes known as split-run testing
- BMT와 다른점은 BMT는 동일한 Input data를 사용하여 결과값을 비교하는 것은 동일하나, 통계적 분석으로 누가 더 우수 하다는 것을 분석한다는 것이 차이임

6.4 METAMORPHIC TESTING
- Metamorphic testing is an approach to generating test cases that deals,
- 변성관계에 의해서 follow up TC가 만들어지고, 그에 따라 Test input 2가 되면, Test output2가 되는 것을 확인하는 Testing 기법

Ch 7 WHITE BOX TESTING OF NEURAL NETWORKS
- 7.1 STRUCTURE OF A NEURAL NETWORK
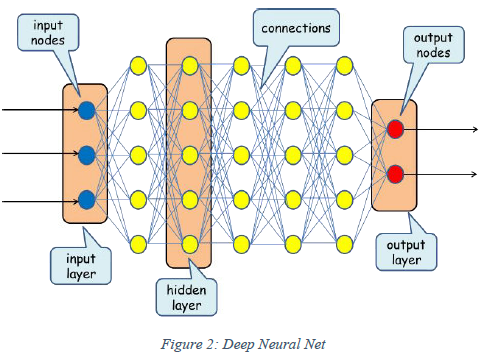
- 7.2 TEST COVERAGE MEASURES FOR NEURAL NETWORKS
- 7.2.1 Neuron Coverage
- activated neurons / the total number of neurons
- 뉴런 커버리지에서 활성값이 "0"을 초과하면 활성화된 뉴런으로 간주함
- 아래 에서 회색 뉴런이 '0'을 초과한 활성 뉴런이면,
- 뉴런 커버리지 = 16/30 *100 = 53%
- 7.2.1 Neuron Coverage

-
- 7.2.2 Threshold Coverage
- exceeding neuron a threshold activation value / the total number of neurons
- Threshold 값은 은 0 ~ 1 사이의 값을 정의하여 사용 함
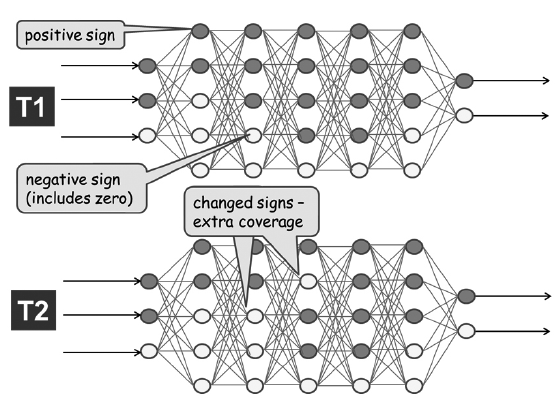
- 7.2.3 Sign Change Coverage (신호변경커버리지)
- 두 개의 테스트, T1과 T2의 결과이다. 회색 뉴런은 활성값이 0보다 큰 뉴런을 표시하고 흰색 뉴런은 활성값이 0개의 이하인 뉴런을 표시한다. T2에서 회색(양성 활성값)인 두 개 뉴런의 부호가 변경되었으며 이제 흰색으로 표시되는 것을 볼 수 있다.
- 따라서 이 두 테스트의 부호 변경 커버리지는 2/30 x 100 = 7% 이다
- 7.2.2 Threshold Coverage
- 7.2.4 Value Change Coverage (값 변경 커버리지)
- 검정색 뉴런에 대한 활성값 1과 활성값 2가 두 테스트에서 합의된 두 개의 변경량과 다른 경우 이 뉴런은 값 변경 커버리지를 달성한 것으로 간주된다. 다른 뉴런 중 어느것도 이 수준의 변경을 달성하지 못하면, 값 변화 커버리지는 1/30 * 100 = 3% 이다

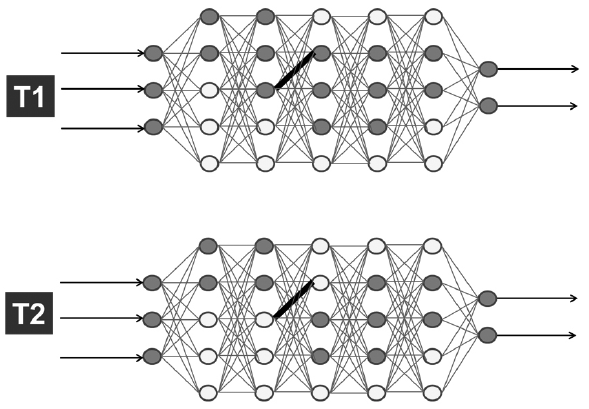
- 7.2.5 Sign-Sign Coverage
- 회색 뉴런은 활성값이 0보다 큰 뉴런을 보여주고(양성), 흰색 뉴런은 활성값이 0 이하인 뉴런을 보여준다(음성). 세 번째 레이어의 한 뉴런이 양성(회색)에서 음성(흰색)으로 부호가 바뀌었고, 다음 레이어에서는 오직 하나의 뉴런이 유사하게 양성에서 음성으로 바뀐 반면, 해당 레이어의 다른 뉴런은 부호를 변경하지 않았음을 알 수 있다.
- 따라서 이 두 가지가 첫 번째 테스트이다. 다른 뉴런 중 어느 것도 이 수준의 변경을 달성하지 못하면, 값 변화 커버리지는 1/30 x 100 = 3% 이다
- 7.2.6 Layer Coverage
- 전체 Layer에서 뉴런이 어떻게 변했는지를 판단하는 지표로서 연구가 더 필요하다 라고만 함
- 7.3 WHITE BOX TESTING TOOLS FOR NEURAL NETWORKS
- DeepXplore – specifically for testing deep neural nets, proposes a white-box differential testing (back-to-back) algorithm to systematically generate adversarial examples that cover all neurons in the network (threshold coverage).
• DeepTest – systematic testing tool for automatically detecting erroneous behaviours of cars driven by deep neural nets. Supports the Sign-Sign coverage for DNNs.
• DeepCover - provides all the levels of coverage defined in this section.
- DeepXplore – specifically for testing deep neural nets, proposes a white-box differential testing (back-to-back) algorithm to systematically generate adversarial examples that cover all neurons in the network (threshold coverage).
Ch 8. TEST ENVIRONMENTS FOR AI-BASED SYSTEMS
- 8.1 TEST ENVIRONMENTS FOR AI-BASED SYSTEMS
- Goal : 2가지 차이점에 대한 설명하라!
- First : AI system 특성 - Large, Complex and Constantly Changing -> AI Testing : Expensive, Realistic, Timescale
- This can make testing in the real world extremely expensive if the full range of possible environments are to be tested,
- the test environments are expected to be realistic
- the testing is to be performed within a sensible timescale.
- Second : AI는 인간의 안전과 연관 -> 실 세계의 위험한 상황에서의 테스트가 필요함
- those AI-Based systems that can physically interact with humans have a safety component, which can make testing in the real world dangerous.
- Both factors indicate the need for the use of virtual test environments.
- Virtual Test environments Benefits
- 위험한 시나리오도 안전하게 test 할 수 있다
- real time으로 test 할 필요는 없다
- 더 싸다
- 다양한 edge case 시나리오 test도 가능
- 물리적으로 가능하지 않은 HW도 고려하여 test 가능하다
- 필요에 따라 측정되고 관찰 할 수 있다
- 실 운영환경에서 테스트 할 수 없는 환경(예로 핵 폭발사고) 등을 test 할 수 있다
- 8.2 TEST SCENARIO DERIVATION
- Test scenarios can be derived from several sources
- System Requirements, Use issues, Automatically reported issues, Accident reports, Insurance data, Collected through legislation, Testing at various levels
- Test scenarios can be derived from several sources
- 8.3 REGULATORY TEST SCENARIOS AND TEST ENVIRONMENTS
- 안전과 연관된 AI 시스템에서는 특히 regulation이 필요하다
Ch 9. USING AI FOR TESTING
- 9.1 INTRODUCTION TO AI-DRIVEN TESTING
- Goal : Recall the three main forms --> 9.2에서 소개함
- 9.2 FORMS OF AI USED FOR TESTING
- SW engineering( and Testing)에 유용한 AI의 3가지 형태, UCL & Facebook의 Mark Harman 교수 의견
- Probabilistic Software engineering : AI는 인간의 행동을 예측하고 분석하는데 사용 될 수 있다.
- Classification, Learning & Prediction : 1) 과제 비용 예측, 2) Machine Learning은 결함을 예측하는데 활용될 수 있다(??? 어떻게는 안나옴)
- Search Based Software Engineering(SBSE) : 검색을 통한 최적문제해결, 예로 최소한의 TC 검색 등
- 예제 : Facebook : SapFix tool 공개 - 자동화 AI 테스트 TOOL
- - https://research.facebook.com/publications/sapfix-automated-end-to-end-repair-at-scale/
- 샙픽스는 AI가 자동으로 앱을 테스트해 버그를 찾고 수정 패치를 개발한다. 그다음 새로운 테스트 케이스를 만들어 재테스트하고 인간 엔지니어의 리뷰를 요구하는 시스템이다.
- 페이스북은 샙픽스를 포함한 전체 디버깅 시스템을 OSS(오픈소스)로 공개중.
- SW engineering( and Testing)에 유용한 AI의 3가지 형태, UCL & Facebook의 Mark Harman 교수 의견
- 9.3 TEST TYPES SUPPORTED BY AI
- some examples uses of AI for testing
- Specification Review : NLP 등을 이용하여
- Specification-Based Script Generaton : AI can generate Test Scrip
- Usage Profiling : AI predicts future use of systems
- Exploratory testing : AI learns and applies heuristics from observation of human
- Crowd Testing : AI analyses response from multiple crowd testers
- Defect manangement : AI classfies and prioritises defect objectively
- User Interface Verification : AI compares web pages and identify perceptible differences
- Web App Spidering (differential testing) : AI identifies issues by repeatedly crawling around web data
- Element Location : AI can finds web elements
- some examples uses of AI for testing
- 9.4 EXAMPLE USE CASES OF AI FOR TESTING
- 9.4.1 Bug prediction
- 다양한 potential factors를 이용하여 bug를 prediction 할 수 있다.
- 9.4.2 Static Analysis (어떤 연관이 있는지? AI와 애매함)
- Static analyzers are automated tools that detect anomalies in source code by scanning programs without running them.
- Although not bug predictors they provide similar guidance – typically identifying where they believe there may be problems in the code
- 9.4.3 Regression Test Optimization
- Regression Test는 많은 시간과 공수가 필요하며, AI는 이를 최적화 할 수 있다
- 9.4.4 Test Input Generation
- Empirical studies show that test input generation tools are good at increasing coverage at little or no extra cost, but there appears to be no measurable improvement in fault detection by using them
- the open source tools AUSTIN for C and EVOSUITE for Java, and Intellitest for C#, which is part of Visual Studio
- 9.4.5 Automated Exploratory Testing
- Dynodroid employs heuristics to reduce the number of inputs and events necessary to reach comparable code coverage as that of Android Monkey.
- Dynodroid : Input generation system for Android apps
- Sapienz uses a multi-objective approach of maximising code coverage and increasing fault revelation, while minimising the length of fault-revealing test sequences
- Saplenz : Multi-objective automated testing for Android app
- Dynodroid employs heuristics to reduce the number of inputs and events necessary to reach comparable code coverage as that of Android Monkey.
- 9.4.1 Bug prediction
'- 배움이 있는 삶 > - AI | Big data' 카테고리의 다른 글
| AI Trustworthiness (0) | 2023.02.13 |
|---|---|
| 자료구조-리스트, 튜플 (콤마로 구분하여 홀수 출력하기) (0) | 2023.01.02 |
| print 함수 다양하게 사용하기 (1) | 2022.12.26 |
| 정수 입력 및 모든 약수 구하기 - 제어문(if) (1) | 2022.12.26 |
| 소금물의 농도 구하기: 연산자 학습 (0) | 2022.12.26 |