2021년 기출문제 - 데이타베이스 정리 입니다
Agenda
1. DBMS - 조인연산방법 : 56번 문제
2. B-트리 연산- 58번 문제
3. 관계연산 - 59번 문제
4. SQL - 참조 무결성 - 65번 문제
5. 확장성 해싱 - 전역깊이, 지역깊이 -66번 문제
6. 릴레이션 분해-74번 문제
7. Apriori. 알고리즘 - 75번 문제
8. 관계연산 - 조인- 68번 문제
9. ERD릴레이션- 약한개체타입( 잘 정리됨)
1. DBMS - 조인연산방법 : 56번 문제
처리유형에 따른 조인분류
- 중첩루프조인
- 정렬합병조인
- 분할해시조인 해시조인
2. B-트리 연산- 58번 문제
- 5-원(way) B tree 연산 설명 : 노드가 5개를 넘어서면 안됨 ( P-1개 노드 수)
B tree 삽입과정에서 오버 플로우가 발생하고, 노드의 분열이 발생한다.
(위 문제 풀이 영상이 존재함)
https://www.youtube.com/shorts/W89cDOGWIzs
https://www.youtube.com/watch?v=Y11hGrKbilU
https://www.youtube.com/watch?v=C7udltJGDiw
3. 관계연산 - 59번 문제
- select(알파), join, projection, division, 차집합 에 대한 자세한 설명자료
📋 관계 대수 & 관계 해석 표현법 💯 총정리
관계 대수 (Relation Algebra) 관계 대수식이란 기존 릴레이션(테이블)들로부터 새로운 릴레이션을 생성하는 절차적 언어 문법이라고 보면 된다. 릴레이션에 대해 기본적인 연산자들을 적용하여 보
inpa.tistory.com
4. SQL - 참조 무결성 제약 조건- 65번 문제
- Data의 입력, 수정, 삭제 과정에서 data의 일관성(consistency)이 깨지는 것을 DBMS 차원에서 방지하는 조건
- CASCADE : 부모 삭제시 자식도 삭제
- RESTRICT : 부모 TABLE에 PK가 존재시만 허용한다
- SET DEFAULT : 디폴트로 세팅한다
- SET NULL : NULL로 세팅한다
직원- EMP(ENO, Name, Super_ENO, E_DNO) , 부서- DEPT(DNO, Dname, Mgr_ENO)
- Super_ENO : 상사직원번호, E_DNO: 소속부서, Mgr_ENO:부서관리자 직원번호
1) 직원 소속부서가 삭제되면 해당 직원은 DEFAULT로 세팅하라
- FOREIGN KEY (E_DNO) REFERENCES DEPT(DNO) ON DELETE SET DEFAULT
2) 해당직원이 삭제되면 상사는 NULL로 세팅하라 --> 문제는 DEFAULT로 세팅하라고 나옴( 정답)
- FOREIGN KEY(Super_ENO) REFERENCES EMP(ENO) ON DELETE SET NULL
3) 부서번호(DNO)가 변경되면 해당부서 소속직원의 소속부서번호도 동일하게 갱신한다
- FOREIGN KEY(E_DNO) REFERENCE DEPT(DNO) ON UPDATE CASCADE
4) 관리직원이 삭제되면, 삭제된 직원이 관리했던 부서의 관리자는 디폴트 관리자로 배치하라
- FOREIGN KEY (Mgr_ENO) REFERENCES EMP(ENO) ON DELETE SET DEFAULT
5. 확장성 해싱 - 전역깊이, 지역깊이 - 아래 내용을 공부 못함- 다시 - 66번 문제
-확장성 해싱 : 디렉토리와 버킷의 집합
https://www.youtube.com/watch?v=NBRiGD0w-_E
- 아래설명이 010, 011 디렉토리 값을 버킷을 가져오면, 지역깊이는 2가 된다고 함
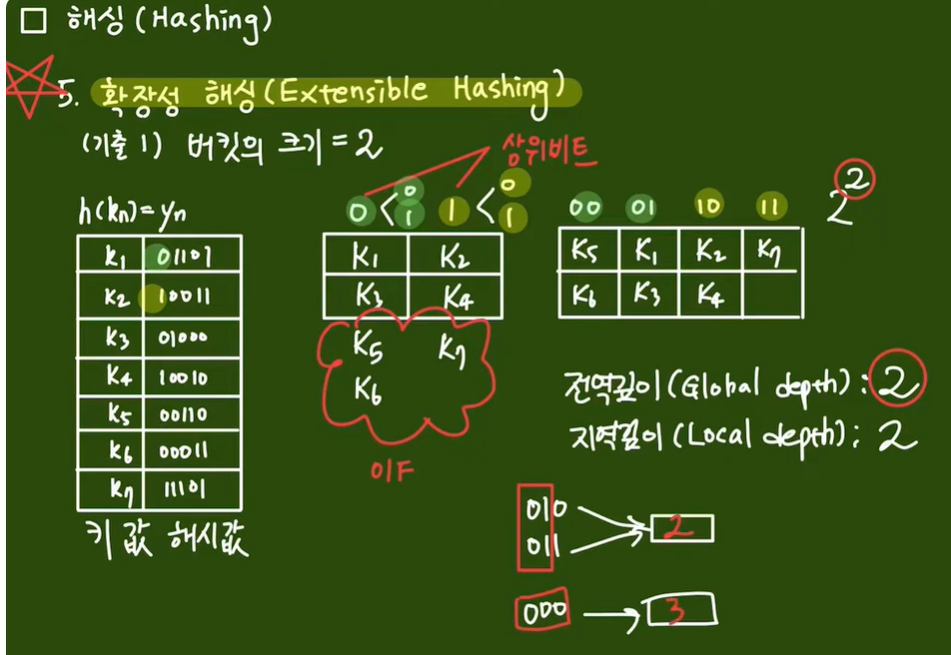
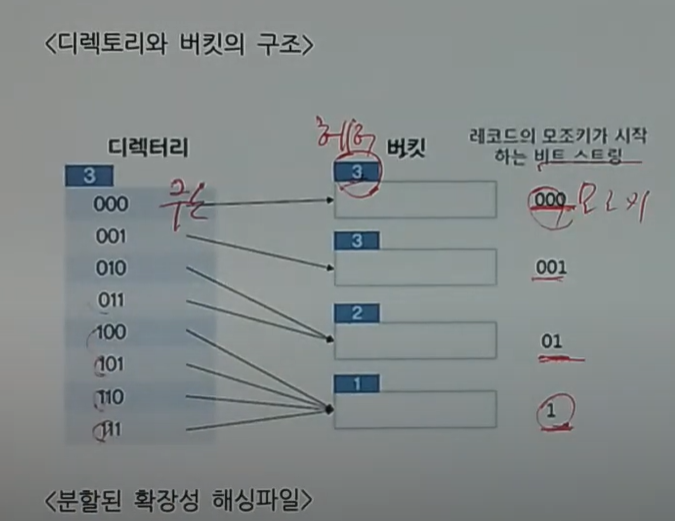

(my 풀이)
참 이해가 안되서 한참을 해맸네요.
1. 전역깊이 : d 값
- 2^d = 디렉토리의 각 수, 위의 문제에서는 8 임
- 2^3 = 8 으로, d = 3 <= 전역 깊이
2. 지역깊이 = p 값, - d >= p + 1
지역깊이는 버킷에 할당이 가능한 cell의 수 , overflow가 발생하지 않게 한다
- p 값은 1 도 될 수 있고, 2도 될 수 있음, -> 그러나, 1 일 경우 010, 011이 할당되고, 나머지는 빈 공간이됨
- 그러고 나머지 4개가 2가 되는데, 그럴 경우 10에서 overflow가 발생함
그러나 해당 p인 나 값이 2일 경우는 overflow 발생하지 않음, 그래서 3,3,2,1 로 지역깊이가 됨
6. 릴레이션 분해-74번 문제

풀이) 정답: 2번
R1, R2에 동시에 함수적 종석성이 존재 함, 이는 부분함수 종속과 이행함수 종속 중 A->B->C 의 순서인 이행함수 종속이 존재 하는 것이기 때문에, R1, R2 중 한 곳에만 함수적 종속성이 만족되어야 함
(AI 설명 및 풀이)
주어진 설명에서 "함수적 종속성 ( R1 \cap R2 \rightarrow R1 )과 ( R1 \cap R2 \rightarrow R2 )를 모두 만족해야 한다"는 부분은 정확히 맞지 않는 표현입니다. 이 문장은 잘못된 진술로, 릴레이션 분해 시 함수적 종속성 보존에 대한 오해를 포함하고 있습니다.
올바른 설명
릴레이션 분해에서 함수적 종속성 보존과 관련된 정확한 조건은 다음과 같습니다:
- 모든 분해된 릴레이션에 대해 원래 릴레이션의 함수적 종속성(FD)이 보존되어야 한다는 것은 맞습니다. 즉, 원래 릴레이션에서 존재하던 모든 함수적 종속성이 분해된 각 릴레이션에서도 유지되어야 합니다.
- 교차 속성( (R1 \cap R2 ) )이 다른 릴레이션의 속성을 결정하는 것은 필수 조건이 아니다.
분해된 릴레이션에서 교차 속성이 다른 릴레이션의 속성을 결정하는 것은 필요하지 않으며, 오히려 이는 부분 종속성을 유발할 수 있는 잘못된 분해일 수 있습니다.
예를 들어, ( R1 \cap R2 )가 ( R2 )의 속성을 결정하는 경우, 이는 ( R2 )가 불필요하게 ( R1 )에 종속된 상태로 남을 수 있으며, 이는 분할의 목적에 어긋납니다. - 함수적 종속성의 보존은 분해된 각 릴레이션에 대해 원래 릴레이션의 모든 종속성이 유지되는 것을 의미하며, 반드시 두 릴레이션 간의 교차 속성이 다른 릴레이션의 속성을 결정해야 한다는 것은 아닙니다.
예를 들어, ( R1 )과 ( R2 )가 분해되었을 때, ( R1 \cap R2 )가 ( R2 )의 속성을 결정하지 않더라도, ( R1 )과 ( R2 ) 각각이 원래 릴레이션의 종속성을 유지하면 충분합니다.
- 교차 속성( (R1 \cap R2 ) )이 다른 릴레이션의 속성을 결정하는 것은 필수 조건이 아니다.
- 그러나 "두 릴레이션 간의 교차 속성이 다른 릴레이션의 속성을 결정해야 한다"는 조건은 잘못된 표현입니다. 이는 다음과 같은 이유로 잘못된 것입니다:
올바른 조건
- 분해된 각 릴레이션에서 원래 릴레이션의 모든 함수적 종속성이 유지되어야 한다는 것이 핵심입니다.
이를 위해서는 교차 속성이 다른 릴레이션의 속성을 결정하지 않도록 주의해야 하며, 각 릴레이션이 독립적으로 종속성을 보존해야 합니다[2][3].
따라서, "교차 속성이 다른 릴레이션의 속성을 결정해야 한다"는 조건은 잘못된 설명이며, 각 분해된 릴레이션이 원래 릴레이션의 종속성을 독립적으로 보존하는 것이 중요합니다.
6. Apriori. 알고리즘 - 75번 문제 - 정답: 3번
연관규칙
Abcd 예서 bcd ->a 일때
Bd ->ac. D-> abc는 고려대상이 아님

- 지지도 : P(AnB) / P(N)
- 신뢰도 (A -> B) : P(AnB) / P(A)
- 상승도 : P(AnB) / P(A) * P(B)
출처: https://investment-ai.tistory.com/entry/2020년-기출문제-데이터-베이스-정리ing [여유가 있는 삶:티스토리]
(AI풀이) - 설명이 이상함, D->A,B,C 신뢰도가 낮아 안된다고 하면, 4번도 정답이 되야 하는데, 결국 BD->AC 때문에 정답이 3번이 되었다는 이야기 인데....왜 그럴지?
연관 규칙의 유효성을 평가할 때 주로 사용하는 지표는 지지도(Support)와 신뢰도(Confidence)입니다:
- 신뢰도: 선행 항목(LHS)이 주어진 경우 후행 항목(RHS)이 발생할 확률입니다. 신뢰도가 낮다면 해당 규칙은 신뢰도 조건을 충족하지 못합니다[3][4].
- 지지도: 전체 거래 중 두 항목 집합이 동시에 발생하는 비율로, 빈발 항목 집합 여부를 판단하는 데 사용됩니다[2][4].
선택지 분석
각 선택지에 포함된 규칙들의 신뢰도와 관련성을 분석해 보겠습니다:
1) BD→AC와 AB→CD
- BD→AC: BD가 주어졌을 때 AC가 발생할 확률이 낮다면 신뢰도가 낮을 수 있습니다.
- AB→CD: AB와 CD는 ABCD의 하위 집합으로, 신뢰도가 낮다면 연관성이 약할 수 있습니다[3].
- 이 두 규칙은 신뢰도가 낮거나 관련성이 약할 가능성이 있습니다.
2) AB→CD와 A→BCD
- A→BCD: A만으로 세 항목 집합인 BCD를 예측하는 것은 신뢰도가 매우 낮을 가능성이 큽니다.
- AB→CD는 신뢰도가 낮을 수 있지만, 상대적으로 A→BCD보다는 신뢰도가 높을 수 있습니다[3][4].
**3) *BD→AC와 D→ABC*
- BD→AC: BD가 주어졌을 때 AC가 발생할 확률이 낮다면 신뢰도가 낮을 수 있습니다.
- D→ABC: D만으로 세 항목 집합인 ABC를 예측하는 것은 신뢰도가 매우 낮을 가능성이 큽니다.
특히, BCD → A가 신뢰도 조건을 충족하지 못했다면 D→ABC 역시 신뢰도가 낮을 가능성이 높습니다.
따라서 이 두 규칙은 신뢰도가 낮아 불필요할 가능성이 큽니다[3][4].
4) A→BCD와 D→ABC
- A만으로 세 항목 집합인 BCD를 예측하거나, D만으로 ABC를 예측하는 것은 신뢰도가 매우 낮습니다.
특히, D→ABC는 BCD → A가 신뢰도 조건을 충족하지 못했다면 신뢰도가 더욱 낮을 가능성이 큽니다[3].
결론: 왜 3번이 정답인가?
BCD → A가 신뢰도 조건을 충족하지 못했다면, 이와 관련된 하위 규칙인 BD→AC와 D→ABC는 신뢰도가 낮을 가능성이 큽니다. 특히, D만으로 ABC를 예측하는 D→ABC는 신뢰도가 매우 낮아 불필요한 규칙으로 간주될 수 있습니다.
따라서 3번 선택지가 정답인 이유는 BD→AC와 D→ABC가 신뢰도가 낮아 더 이상 고려할 필요가 없는 규칙들로 짝지어졌기 때문입니다[3][4].
- 한 항목집합이 "빈발항목집합" 이면, 이 항목집합의 모든 부분집합은 " 빈발항목집합" 이다

- 예로 이마트에 맥주와 과자의 연관규칙을 찾아내는 최초의 알고리즘 : 아프리얼 알고리즘
https://www.youtube.com/watch?v=6X6hSrXG9no
7. 관계연산 - 조인- 68번 문제
2021년 기출 - 68번
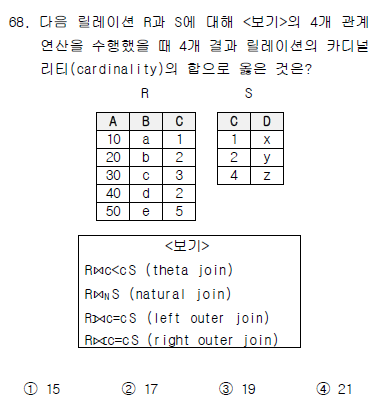
정답 : 17
- 써타조인 : 카디널리티 5
- 자연조인 : 카디널리티 3
- left outer join : 카디널리티 5
- right outer join : 카디널리티 4
(아래 연산, 관계 연산, 관계대수 등에 대한 공부하기 좋음 - 합집합, 조인 등에 관한 내용)
https://www.youtube.com/watch?v=h7AZAWfYH8k
https://swingswing.tistory.com/12
SQL 조인_이너 조인, 아웃터 조인, 세타 조인, 동등 조인, 자연 조인, 세미 조인, 교차 조인, 셀프
▣ SQL 조인_이너 조인, 아웃터 조인, 세타 조인, 동등 조인, 자연 조인, 세미 조인, 교차 조인, 셀프 조인 1. INNER JOIN 교집합(A∩B) 2. LEFT OUTER JOIN 교집합 연산 결과와 차집합 연산 결과를 합친것( (A
swingswing.tistory.com
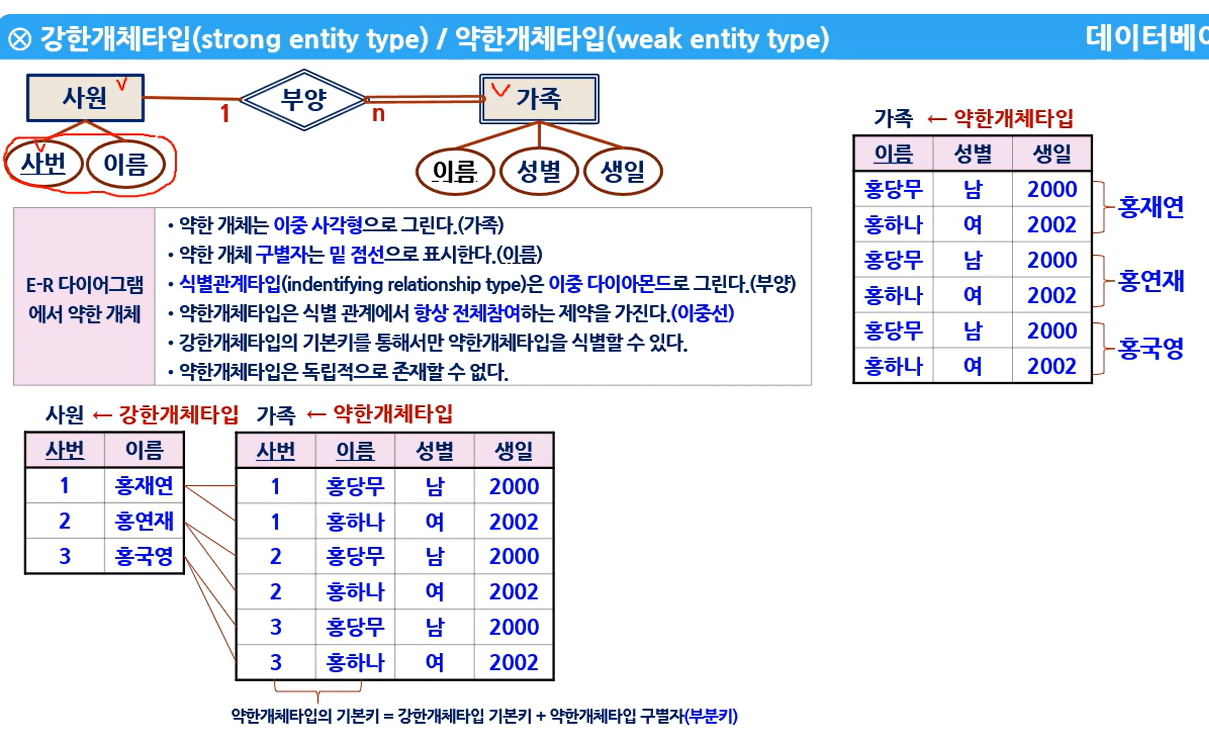
8. ERD 릴레이션 - 약한 개체타입
- 아래 동영상은 공무원 대비 동영상으로 잘 정리됨 : ERD 릴레이션과 강한개체타입/ 약한개체 타입에 대한 설명임
https://www.youtube.com/watch?v=Wk4WMtMNIWw&t=922s
아래 처럼 1:n 관계에서 관계 스키마를 생성하나, 반드시 그런것은 아니다, 만약에 n 쪽의 스키마에 지도 스키마의 속성을 포함할 수 있다면, 그것도 가능하다. (2022년 계리직 문제에서 처럼)
감리사 문제에서도 유사한 문제가 출제되었다. 다만, 약한개체관계타입 (= 이중선) 일때 관계 스키마를 생성하지 않고, 약한객체스키마에 포함하는 것이 정답이었음
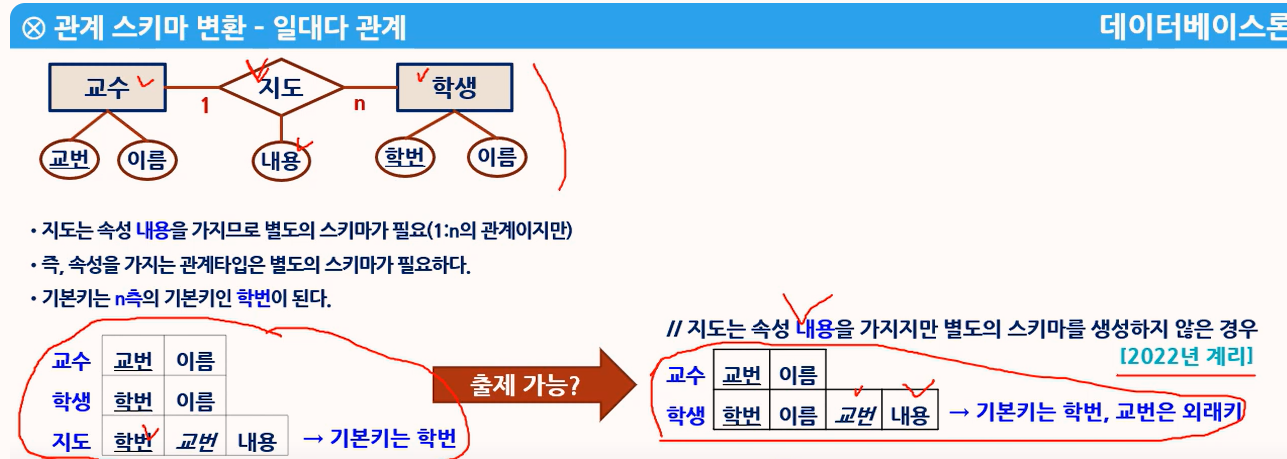
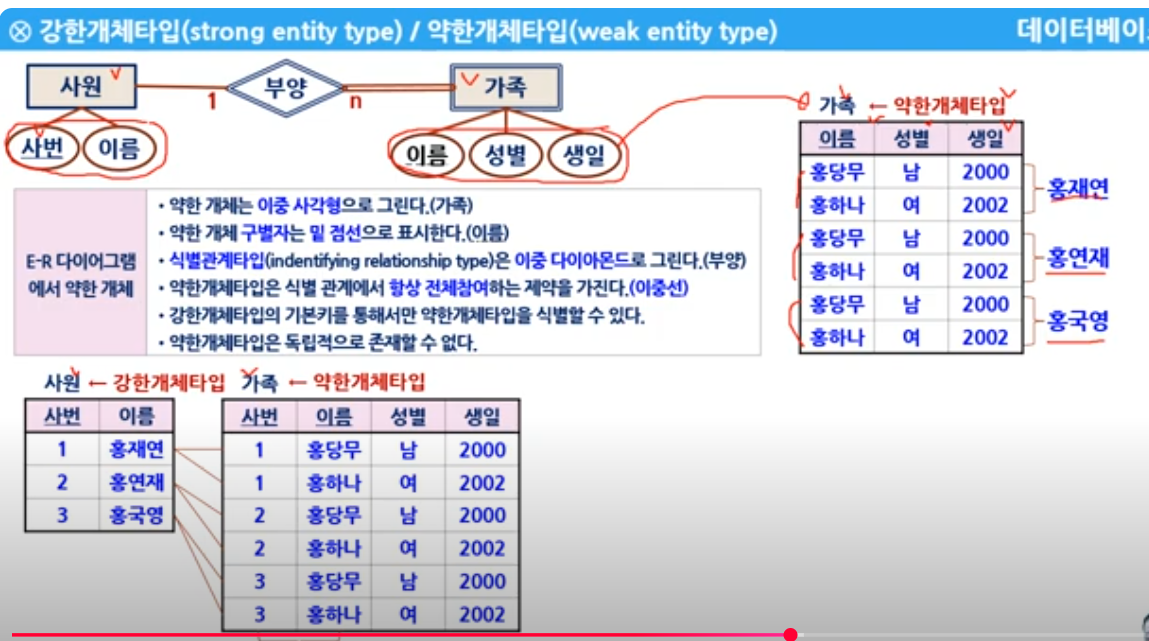
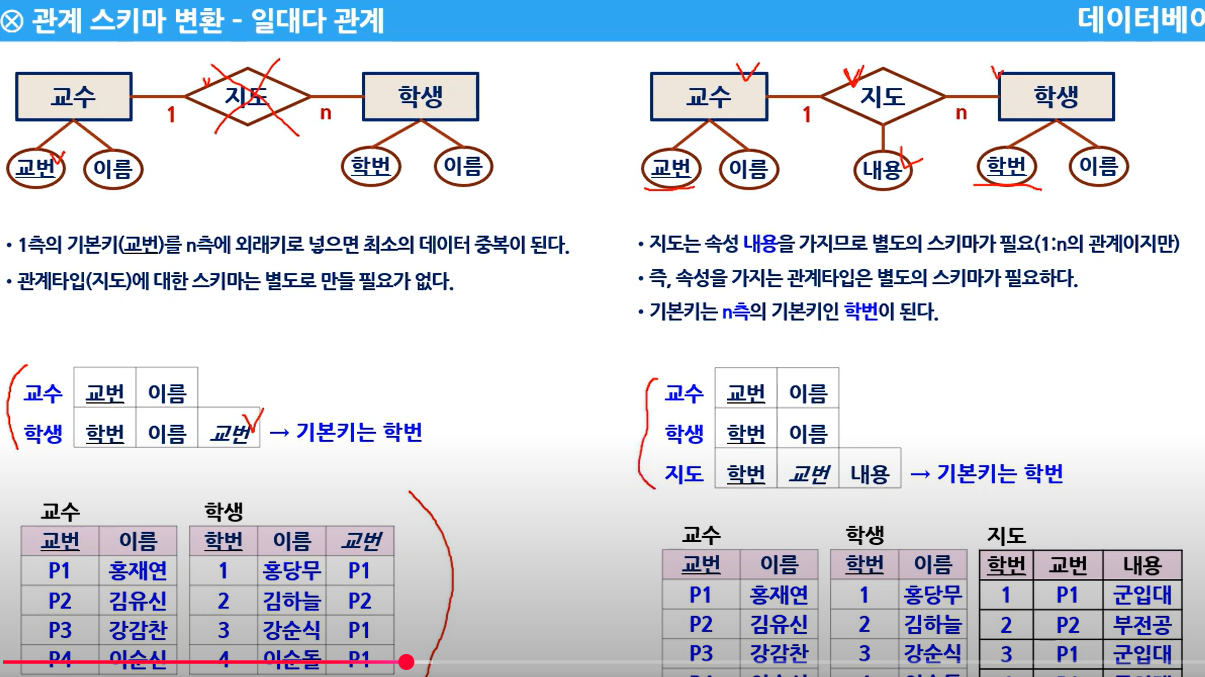
1) 1: n 관계
- 관계(수강) 테이블이 속성이 없을경우 = 스키마를 생성하지 않는다 (스카마 수 : 2 )
- 관계(수강) 테이블에 속성이 있을 경우 = 관계테이블도 스키마를 생성한다 (스키마 수 : 3)
- 관계타입의 스키마의 기본키는 n 관계의 기본키를 기본키로 한다 (아래 오른쪽 관계의 설명으로 보면, 지도 스키마의 기본키는 학번으로 함)
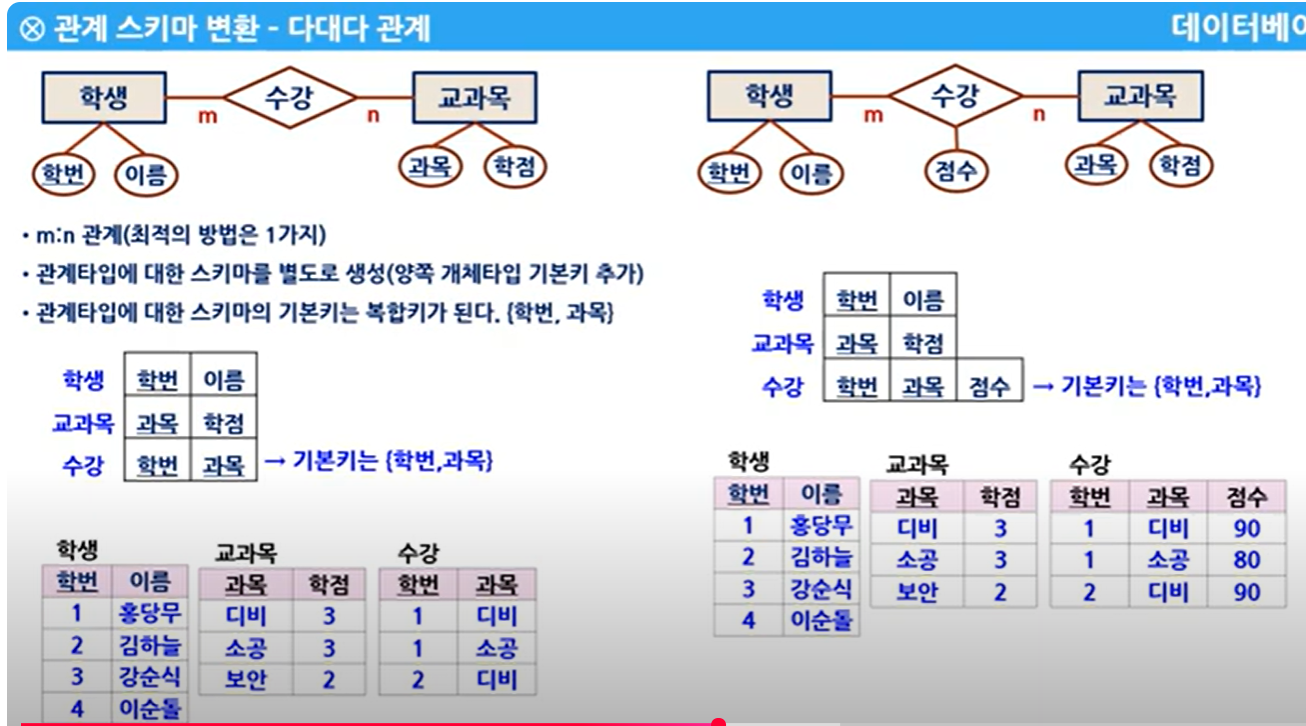
2) n:m 관계
- 관계 테이블에 속성의 유무와 상관없이 스카마를 생성한다
= 아래 m:n 관계에서는 모두 3개의 스키마가 생성해야 한다.
- 강한객체타입/ 약한 객체타임
'- 배움이 있는 삶 > - 데이타베이스' 카테고리의 다른 글
| 2020년 기출문제 - 데이터 베이스 정리 (14) | 2025.04.15 |
|---|---|
| 2024년 기출문제 - 데이타베이스 (6) | 2025.04.09 |
| 데이타베이스 - 기본 과정 정리(1차 완료) (5) | 2025.03.17 |
| 2023년 기출문제-데이타베이스 - 다시 (6) | 2025.03.15 |
| 2022년 기출문제-데이타베이스ㅡ다시 (5) | 2025.03.04 |



