반응형
1.Open AI
- ChatGPT에게 물어보기
- GPT-4o 성능평가 방법
2. Amazon guide
3. 논문
1. ChatGPT에게 물어 보기
생성형 AI 모델의 검증 방법은 여러 측면을 고려해야 합니다. 일반적으로 다음과 같은 단계를 따릅니다:
1. **정성적 평가 (Qualitative Evaluation)**:
- 모델이 생성한 샘플을 직접 평가하고, 품질과 일관성을 판단합니다.
- 생성된 샘플의 품질, 다양성, 유용성 등을 고려합니다.
2. **정량적 평가 (Quantitative Evaluation)**:
- 생성된 결과를 자동으로 측정하고 평가하는 지표를 사용합니다.
- BLEU, ROUGE, Perplexity 등의 지표를 활용하여 언어 생성 모델의 성능을 평가합니다.
3. **인간 평가 (Human Evaluation)**:
- 인간 판단을 기반으로 생성된 결과를 평가합니다.
- 인간 평가자를 통해 생성된 결과의 품질, 자연스러움, 정보 전달 등을 평가합니다.
4. **대규모 테스트 (Large-scale Testing)**:
- 다양한 데이터셋과 환경에서 모델을 테스트하여 일반화된 성능을 확인합니다.
- 모델이 다양한 문맥에서 얼마나 잘 작동하는지 확인합니다.
5. **윤리적 고려사항 (Ethical Considerations)**:
- 생성된 결과의 윤리적 문제를 고려하고 검토합니다.
- 모델이 생성한 콘텐츠가 유해하거나 모순된 경우를 식별하고 수정합니다.
이러한 다양한 방법을 통해 생성형 AI 모델의 성능을 평가하고 향상시킬 수 있습니다.
2. GPT-4o 성능평가 방법

1. AMAZON Guide : https://aws.amazon.com/ko/what-is/generative-ai/
자동 및 수동 테스트 프로세스를 개발하여 결과를 검증하고 생성형 AI 시스템에서 발생할 수 있는 모든 유형의 시나리오를 테스트합니다. 다양한 방식으로 애플리케이션을 시험해보고 결과를 문서화하는 다양한 베타 테스터 그룹을 구성합니다. 또한 테스트를 통해 모델이 지속적으로 개선되므로 예상 결과와 반응을 더 잘 제어할 수 있습니다.
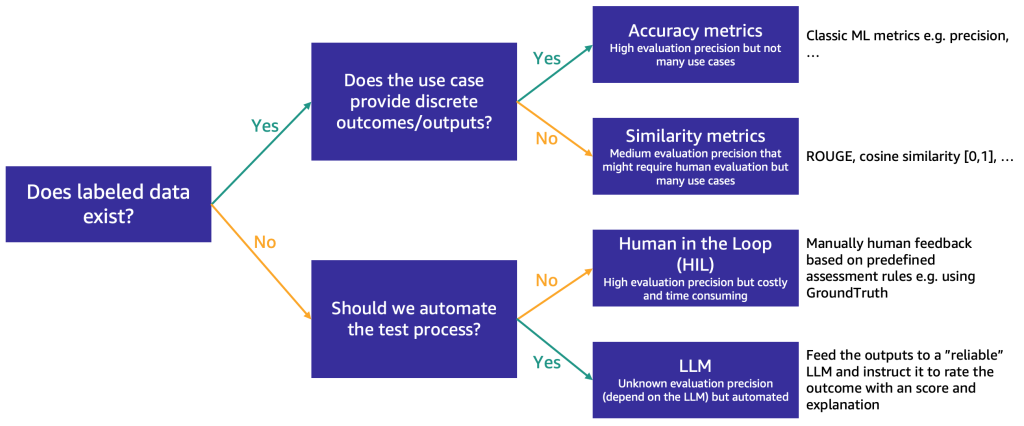
BLEU, ROUGE, Perplexity 지표 란
<참고문헌>
1. ChatGPT
반응형
'- 배움이 있는 삶 > - AI | Big data' 카테고리의 다른 글
| AI관련 site : OpenAI vs Google AI vs Meta vs Amazon etc (0) | 2024.05.28 |
|---|---|
| Gemini를 활용한 SW 프로세스 개선 연구 (0) | 2024.05.23 |
| GPT-4o 성능평가 (0) | 2024.05.21 |
| LLM 성능평가 모델 논문 (0) | 2024.05.21 |
| Data Science 중급 (0) | 2024.05.21 |

